BigDL Spark deep learning library VM now available on Microsoft Azure Marketplace
This blog was co-authored by Sergey Ermolin, Intel and Patrick Butler, Microsoft
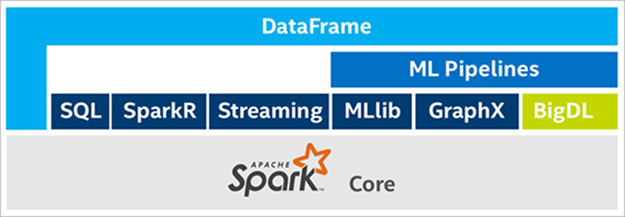
BigDL deep learning library is a Spark-based framework for creating and deploying deep learning models at scale. While it has previously been deployed on Azure HDInsight and Data Science VM, it is now also available on Azure Marketplace as a fixed VM image, representing a further step by Intel to reduce deployment complexity for users.
Because BigDL is an integral part of Spark, a user does not need to explicitly manage distributed computations. A BigDL application provides high-level control “knobs”, such as the number of compute nodes, cores, and batch size, a BigDL application also leverages stable Spark infrastructure for node communications and resource management during its execution. BigDL applications can be written in either Python or Scala and achieve high performance through both algorithm optimization and taking advantage of close integration with Intel’s Math Kernel Library (MKL).
For more information about BigDL features and capabilities, refer to the GitHub BigDL overview and Intel BigDL framework.
What is the Microsoft Azure Marketplace? The Azure Marketplace is an online applications and services marketplace that enables start-ups, independent software vendors (ISVs), and MSP/SIs to offer their Azure-based solutions or services to customers around the world. Learn more information on the Azure Marketplace.
Introduction
This post describes two use case scenarios to deploy BigDL_v0.4 in Azure VMs:
- First scenario: Deploying an Azure VM with a pre-built BigDL_v0.4 image and running a basic deep learning example.
- Second scenario: Deploying BigDL_v0.4 on a bare-bones Ubuntu VM (for advanced users).
First scenario: Deploying a pre-built BigDL_v0.4 VM image:
Log in to your Microsoft Azure account. BigDL requires you to have an Azure subscription. You can get a free trial by visiting BigDL offering on Azure Marketplace and clicking Get it now.

You should see the following page. Click on the Create button at the bottom.

Enter the requested information in the fields at the prompts. Note that Azure imposes syntax limitations on some of the fields (such as using only alphanumeric characters and no CAPS). Use lowercase letters and digits and you will be fine. Use the following three screenshots for guidance.

Spark is memory-intensive, so select a machine with a larger amount of RAM. Note that not all VM types and sizes are available in certain regions. Refer to this Azure page for more info. For simple tasks and testing, the virtual machine displayed in the following screenshot will meet requirements:

After the VM is provisioned, copy its public IP address. Note that this public IP address will change every time you stop and restart your VM. Keep this in mind if you are thinking of BigDL automation.

After deployment, you can modify the IP address provided in the resource group and set it up as a static IP address:

You are now ready to SSH into your BigDL VM. You can use your favorite SSH client. For this example, MobaXterm is used.
Enter the IP address and the username you selected when creating the VM.


Check the versions of installed dependencies:

Before using pre-installed BigDL, you will need to change ownership of the directory.

BigDL was pre-installed into the bigdlazrmktplc directory. Yet ‘testuser’ does not have full privileges to access it.
To change this, type:
$sudo chown -R testuser:testuser bigdlazrmktplc

Now ‘testuser’ owns the bigdlazrmktplc directory.
Finally, test that BigDL actually works in this VM by entering the following commands:
$cd bigdlazrmktplc/BigDL $export SPARK_HOME=/usr/local/spark/spark-2.2.0-bin-hadoop2.7 $export BIGDL_HOME=/home/bigdlazrmktplc/BigDL $BigDL/bin/pyspark-with-bigdl.sh --master local[*]
If the commands are successful you will see the following:

At the command prompt, copy and paste the following example code, the source can be found on GitHub
from bigdl.util.common import *
from pyspark import SparkContext
from bigdl.nn.layer import *
import bigdl.version
# create sparkcontext with bigdl configuration
sc = SparkContext.getOrCreate(conf=create_spark_conf().setMaster("local[*]"))
init_engine() # prepare the bigdl environment
bigdl.version.__version__ # Get the current BigDL version
linear = Linear(2, 3) # Try to create a Linear layer
If the commands are successful, you will see the following:

BigDL is now ready for you to use.
Second Scenario: Deploying BigDL_v0.4 on a bare-bones Ubuntu Azure VM
First, you will need to create an Azure subscription. You can get a free trial by navigating to BigDL offering on Azure Marketplace and clicking Get it now.
Log in to the Azure Portal, go to New, and select Ubuntu server 16.04 LTS VM (LTS = Long Term Support).

Enter the basic VM attributes using only lower-case letters and numbers.

For Spark jobs you want to select VMs with a large amount of RAM available.

After your VM has been created, you can SSH into it using the username and password which you created previously.
Copy the Public IP address of the VM:

This creates a very basic Ubuntu machine, so you must install the following addtional components to run BigDL:
- Java Runtime Environment (JRE)
- Scala
- Spark
- Python packages
- BigDL
Installing the Java Runtime Environment (JRE)
At the command prompt, type the following commands:
$sudo add-apt-repository ppa:webupd8team/java $sudo apt-get update $sudo apt-get install oracle-java8-installer $sudo apt-get install oracle-java8-set-default
Confirm the installation and JRE version by typing
$java -version
Installing Scala and confirming version
At the command prompt, type the following commands:
$sudo apt-get install scala $scala -version
Installing Spark 2.2.x
At the command prompt, type the following commands:
$sudo wget http://mirrors.ibiblio.org/apache/spark/spark-2.2.0/spark-2.2.0-bin-hadoop2.7.tgz $sudo tar xvzf spark-2.2.0-bin-hadoop2.7.tgz $rm spark-2.2.0-bin-hadoop2.7.tgz $sudo mkdir /usr/local/spark $sudo mv spark-2.2.0-bin-hadoop2.7 /usr/local/spark Verify Spark installation: $cd /usr/local/spark/spark-2.2.0-bin-hadoop2.7/ $./bin/spark-submit –version

Installing BigDL
The main repo for BigDL downloadable releases.
For Spark 2.2.0 and Scala 2.11.x, select Dist-spark-2.2.0-scala-2.11.8-all-0.4.0-dist.zip
At the command prompt, type the following commands:
$cd ~ $mkdir BigDL $cd BigDL $sudo wget https://s3-ap-southeast-1.amazonaws.com/bigdl-download/dist-spark-2.2.0-scala-2.11.8-all-0.4.0-dist.zip $sudo apt-get install unzip $unzip dist-spark-2.2.0-scala-2.11.8-all-0.4.0-dist.zip $rm dist-spark-2.2.0-scala-2.11.8-all-0.4.0-dist.zip
Installing Python 2.7 packages
Ubuntu 16x on Azure comes with pre-installed python 2.7. However, there are a couple of additional packages that must be installed.
At the command prompt, type the following commands:
$sudo apt-get install python-numpy $sudo apt-get install python-six
Update all packages and dependencies by typing
$sudo apt-get update
Verify BigDL installation
The instructions to verify that BigDL was installed correctly are available.
At the command prompt, type the following commands:
$export SPARK_HOME=/usr/local/spark/spark-2.2.0-bin-hadoop2.7 $export BIGDL_HOME=/home/bigdlazrmktplc/BigDL
Launch PySpark (from BigDL directory)
$bin/pyspark-with-bigdl.sh --master local[*]
At the prompt, copy and paste the following code, this code can also be found at Github.
from bigdl.util.common import *
from pyspark import SparkContext
from bigdl.nn.layer import *
import bigdl.version
# create sparkcontext with bigdl configuration
sc = SparkContext.getOrCreate(conf=create_spark_conf().setMaster("local[*]"))
init_engine() # prepare the bigdl environment
bigdl.version.__version__ # Get the current BigDL version
linear = Linear(2, 3) # Try to create a Linear layer
You should see the following:
creating: createLinear cls.getname: com.intel.analytics.bigdl.python.api.Sample BigDLBasePickler registering: bigdl.util.common Sample cls.getname: com.intel.analytics.bigdl.python.api.EvaluatedResult BigDLBasePickler registering: bigdl.util.common EvaluatedResult cls.getname: com.intel.analytics.bigdl.python.api.JTensor BigDLBasePickler registering: bigdl.util.common JTensor cls.getname: com.intel.analytics.bigdl.python.api.JActivity BigDLBasePickler registering: bigdl.util.common JActivity >>>
Finally, install Maven to allow you to build BigDL applications by typing the following:
$sudo apt-get install maven
Your VM is now ready for running deep learning examples at scale.
You can find many more examples, how-to guides, and documentation at the following links:
Source: Azure Blog Feed