Lightning fast query performance with Azure SQL Data Warehouse
Azure SQL Data Warehouse is a fast, flexible and secure analytics platform for enterprises of all sizes. Today we announced significant query performance improvements for Azure SQL Data Warehouse (SQL DW) customers enabled through enhancements in the distributed query execution layer.
Analytics workload performance is determined by two major factors, I/O bandwidth to storage and repartitioning speed, also known as shuffle speed. In this previous blog post, we described how SQL DW caches relevant data to take advantage of NVMe based local storage. In this blog post, we will go under the hood of SQL DW, to see how the shuffling speed has improved.
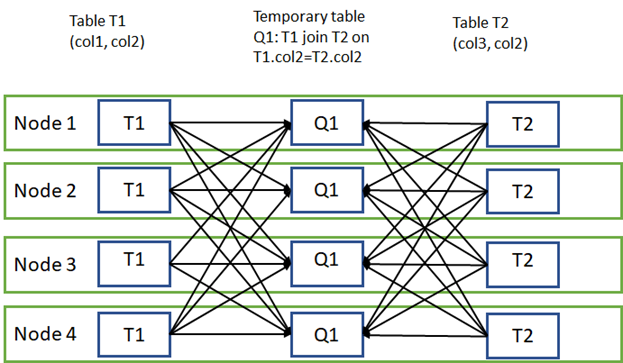
Data movement is an operation where parts of the distributed tables are moved to different nodes during query execution. This operation is required where the data is not available on the target node, most commonly when the tables do not share the distribution key. The most common data movement operation is shuffle. During shuffle, for each input row, SQL DW computes a hash value using the join columns and then sends that row to the node that owns that hash value. Either one or both sides of join can participate in the shuffle. The diagram below displays shuffle to implement join between tables T1 and T2 where neither of the tables is distributed on the join column col2.

Another conventional data movement operation is the broadcast where table parts are copied from the source node to all the other SQL DW nodes, for example when joining a dimension and a fact table, the dimension table is commonly broadcast. SQL DW query optimizer chooses the appropriate data movement type to minimize the number of rows transferred.
Until now the data movement operations were done by SQL DW Data Movement Service (DMS) component, seen in the diagram below.

To implement shuffle, Data Movement Service copies rows out of SQL Server Engine, hashes them and sends them to the appropriate instance of DMS on other nodes, where DMS copies rows to the local temporary tables using SQL Server BulkCopy API. Reading rows out of SQL Server is a single threaded operation and can be a bottleneck.
SQL DW now integrates data movement directly into SQL Server engine. This integration allows SQL DW data movement to benefit from full multi-core parallelism available and use batch mode execution for data movement operations as well.
Combined with the use of Azure Accelerated Networking, SQL DW can move data up to one gigabyte a sec per node, significantly improving queries that join data from tables not aligned on their distribution keys. The diagram below shows the SQL DW operating shuffle using SQL DW instant data movement mode:

When SQL DW moves data in the instant mode, the intermediate results get produced and sent to all required nodes using all available CPU cores, thus taking advantage of the multi-core trend. Data is written in a compact batch-oriented row format directly to the remote node’s temporary database, with minimal per row overhead, as the data does not cross SQL Server Engine front-door which performs data validations which add a significant cost.
This capability is available now for all existing and new customers of Compute Optimized Gen2 tier of SQL DW. SQL DW instant data movement is used for queries that do not use external data; PolyBase queries remain using Data Movement Service. As data volumes and the need for faster insights grow, we remain committed to innovating to deliver the best possible query performance for all our customers.
- Read more about how Azure SQL Data Warehouse offers industry-leading query performance in this GigaOm report.
- Get started with Azure SQL Data Warehouse for free today.
Source: Big Data