Experimentation using Azure Machine Learning
We are pleased to announce public preview refresh of the Azure Machine Learning (AML) service. The refresh contains many new improvements that increase the productivity of data scientists.
In this post, I want to highlight some of the improvements we made around machine learning experimentation, which is the process of developing, training, and optimizing a machine learning model. Experimentation also often includes auditing, governing, sharing, repeating, understanding and other enterprise-level functions. Read more about this high-level overview of the Azure Machine Learning service strategy and direction.
Machine Learning experimentation
The process of developing machine learning models for production involves many steps. First, the data scientist must decide on a model architecture and data featurization. Next, they must train and attempt to tune these models. This requires them to manage the compute resources to execute and scale out training, collect the training data and make it available to the target compute resource. They also must keep track of the different (hyper-)parameter combinations and model versions used along the way, and which results they yielded. All that is often embedded in a complex data flow needed to acquire and prepare the data on the preprocessing side and to post-process and deploy the model on the other.
To help the data scientist be more productive when performing all these steps, Azure Machine Learning offers a simple-to-use Python API to provide an effortless, end-to-end machine learning experimentation experience. Supported by the Azure Cloud, it provides a single control plane API to seamlessly execute the steps of machine learning workflows. These workflows can be authored within a variety of developer experiences, including Jupyter Python Notebook, Visual Studio Code, any other Python IDE, or even from automated CI/CD pipelines. AML offers a uniquely simple but powerful experience to enable the following:
- Training in the cloud – Users can leverage the power of Azure offerings with minimal onboarding friction by handling authentication, workspace creation, data source management, and model training all in one place.
Data scientists can easily package the training code and library dependencies for reproducible data science into a docker container, and hand off the resulting model artifacts to DevOps for production deployment. - Highly scalable and flexible model training – Users can provision compute with a few lines of Python, and easily scale out to parallel and distributed training. They are able to take advantage of AML functionality without having to modify their existing training code
- Rapid iteration and traceability of models – run history, hyperparameter tuning. Users can tune the hyperparameters of their models using AML’s hyperparameter optimization service, view the run history of all training jobs kicked off through AML, and select the best performing models for their scenario for deployment. By tracking each training run and each model that gets deployed, AML provides an audit trail and enables traceability of machine learning activities.
- Automatically find an algorithm and associated pipeline based on your data – Based on a given labelled dataset that the user wants to build a model for, AML’s automated machine learning will automatically perform algorithm and data pipeline/featurization steps selection and generate a high-quality model.
- Describe experiment steps as a pipeline for repeatability and sharing – AML’s pipelines feature allows the user, for instance, to capture the different steps of retraining and deploying a model and to define them in an execution graph to be run repeatedly and be shared with colleagues or the community.
To illustrate how experimentation with AML accelerates the machine learning development process, let’s look at an SDK example. We are starting off with a very common example of a TensorFlow model for the MNIST dataset. It is MNIST with summaries, a TensorFlow tutorial script from the TensorFlow github repository The tutorial trains a simple neural network and logs various statistics throughout the process.
Setting up a workspace
In AML, data scientists will use workspaces to manage and carry out experiments. The workspace is the central location for a team to collaborate and it manages access to compute targets, data storage, models created, docker images created, webservices deployed and it keeps track of all the experiment runs that were performed with it. Data scientists can manage the authorization and creation of workspaces and experiment from the Python SDK.

In the snippet below, we are creating a workspace called Demo in the resource group Contoso which resides in the given subscription. The workspace will be created in the Azure region eastUS2.
from azureml.core import Workspace
ws = Workspace.create(name='Demo',
subscription_id='12345678-1234-1234-a0e3-b1a1a3b06324',
resource_group='Contoso',
location='eastus2')
Find more details on AML workspaces.
Training a Model in the cloud
Typically, one of the most time-consuming phases of machine learning is training. It is often computationally intensive and can require a large amount of compute resources. The AML SDK distills the process of managing and provisioning compute into a few API calls, regardless of whether your training job runs on one a single core or scales to hundreds of GPUs. Using the SDK, you can train locally on your own machine, on an Azure Virtual Machine (VM), on an Azure BatchAI cluster, or on any Linux machine that can be reached from Azure.
Here, we will provision and attach an Azure BatchAI cluster of “STANDARD_NC6” VMs on our workspace – STANDARD_NC6 VMs features 1 Nvidia Tesla K80 GPU, see here for a list of Azure VM sizes. The cluster we create is set to autoscale from 0 to up to 10 nodes, so we only bring up and pay for compute while jobs are running on the cluster.
from azureml.core.compute import ComputeTarget, BatchAiCompute
provisioning_config = BatchAiCompute.provisioning_configuration(vm_size = "STANDARD_NC6",
autoscale_enabled = True,
cluster_min_nodes = 0,
cluster_max_nodes = 10)
nc6_cluster = ComputeTarget.create(ws,
name = "nc6_cluster",
provisioning_configuration=provisioning_config)
The following code will create an instance of the TensorFlow estimator class, which provides a convenient wrapper to configure a TensorFlow job in AML. Here we specify the current directory (‘.’) as the source_directory to send to the compute target provided – all files and subfolders in this folder will be made available to the process before it is started on the nc6_cluster as compute target. The script that will be invoked will be the mnist_with_summaries.py script which we had downloaded at the beginning – the script parameters listed will be passed to the script just like they would for local execution. Lastly, we specify that we want to run this job with GPU docker support.
In the next line, we submit the script for execution per the specs above, and we have it be tracked under the experiment named ‘mnist’. An experiment is merely a collection of script submissions, grouped together under a single name for convenient retrieval. As a result of the submit call, AML will create a docker image that meets the requirements of the job – namely having TensorFlow for GPU installed along with the necessary Nvidia drivers for optimal docker GPU performance on Azure. Once the docker image is built, it is cached for future execution and then staged onto the chosen compute node of the Batch AI cluster provided. This is a single node job, so only one node will be provisioned to run the job.
from azureml.train.dnn import TensorFlow
from azureml.core import Experiment
tf_estimator = TensorFlow(source_directory='.',
compute_target=nc6_cluster,
entry_script='mnist_with_summaries.py',
script_params={'--max_steps':5000, '--log_dir': './logs',},
use_gpu=True)
run = Experiment(ws, 'mnist').submit(tf_estimator)
Monitoring a training run
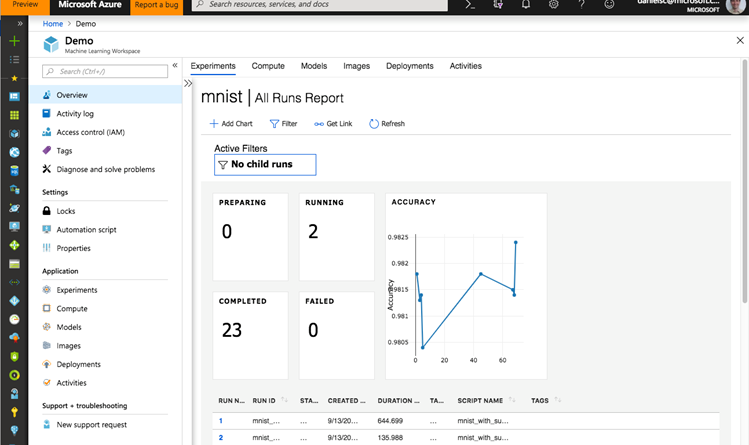
Azure ML integrates with Jupyter Notebooks, allowing the data scientist to view the status of the executed run inside the notebook. The widget shows meta information of the run along with the output logs and the metrics that were logged by the script while it is executing. Whenever a metric is reported more than once, the widget will show a plot to visualize the metric over the different steps. Here we added logging code to the script to log the accuracy of the model over the test set as Accuracy_test.

If the training script is producing Tensorboard log outputs (and is writing these to the ’./logs’ directory on the compute target), these can be easily transferred from the compute target to the local machine by running AML’s Tensorboard downloader class. For convenience, we also start a Tensorboard instance pointing to the log file location and provide the local URL to navigate to. Note that the logs get streamed while the job is still running.

Training can also be performed on multiple nodes. Please visit this article for details on distributed training with TensorFlow.
Tuning the Hyperparameters of a Model
An important aspect of machine learning is hyperparameter tuning. Data scientists typically configure and test many different combinations of hyperparameters to improve model accuracy. AML provides a hyperparameter tuning service, which offers Random, Grid and Bayesian parameter sampling, supports early termination and manages the jobs creation and monitoring process for the user.
In the code below, we kick off a hyperparameter tuning run using the Python SDK. We choose a random parameter sampling strategy and provide the ranges for the learning rate and the dropout hyperparameters in the RandomParameterSampling object. Then, we define the early termination policy to be used as BanditPolicy – this will terminate jobs that are not performing well and are not likely to yield a good model in the end. Concretely, this configuration will evaluate jobs every 10 steps and will terminate jobs that are not within 15 percent slack of the best performing job at that particular step. On larger models, this strategy typically saves about 50 percent of compute time with no impact on the performance of the best model trained.
Lastly, we configure the hyperparameter run using the tf_estimator we had defined above, the parameter sampling, and the early termination policy provided. In addition, we need to tell the optimizer which metric to look at (Accuracy_test) and that it should be maximized. Lastly, we set the number of runs we want to perform to 100, running 10 concurrently. Then we submit the run.
from azureml.train.hyperdrive import *
# define hyperparameter sampling space
ps = RandomParameterSampling(
{
'--learning_rate': uniform(0.000001, 0.1),
'--dropout': uniform(0.5, 0.95)
}
)
# define early termination policy
early_termination_policy = BanditPolicy(slack_factor = 0.15, evaluation_interval=10)
# configure the run
hyperdrive_run_config = HyperDriveRunConfig(estimator = tf_estimator,
hyperparameter_sampling = ps,
policy = early_termination_policy,
primary_metric_name = "Accuracy_test",
primary_metric_goal = PrimaryMetricGoal.MAXIMIZE,
max_total_runs = 100,
max_concurrent_runs = 10)
# start the run
hd_run = Experiment(ws,'mnist').submit(hyperdrive_run_config)
# launch the widget to view the progress and results
RunDetails(hd_run).show()
Again, the status of the hyperdrive sweep can be tracked in the Jupyter Notebook – here we see all meta information about the hyperparameter sweep along with the list of runs and their status. Below, we see the target metric for all runs plotted together. As you can see, poor runs were terminated early on, while more promising runs were not cancelled.


Find more details on hyperparameter tuning.
Automated Machine Learning
In the above example, we started out with a given model that the data scientist would modify and then tune. But often time it is not clear which type of model will yield good results for a given problem. So, data scientists run multiple ML training jobs to find the right model. For example, for a machine learning classification problem, a data scientist could be running data through many different classifiers available such as SVM, Logistic Regression, Boosted Decision Tress etc. In addition, the user is also trying many different featurization pipelines for each of the algorithms. The only way to really know which classifier & featurization is best still requires trying out many different combinations. If done manually, this would result in a lot of training jobs to run and keep track of. With AML’s automated machine learning, users can build a high-quality model automatically as AML will train the model for the dataset by trying several combinations of algorithm and featurization.
Again, the AML SDK will allow the user to start and monitor the runs easily in a Jupyter notebook. Here we are configuring a classification task to be run on the nc6 cluster we created above. 20 different algorithms will be tried, 10 concurrently.
from azureml.train.automl import AutoMLConfig
from azureml.train.automl.constants import Metric
from get_data import get_data
automl_config = AutoMLConfig(task = 'classification',
path='.',
compute_target = nc6_cluster,
data_script = "get_data.py",
max_time_sec = 600,
iterations = 20,
n_cross_validations = 5,
primary_metric = Metric.AUCWeighted,
concurrent_iterations = 10)
remote_run = Experiment(ws,'mnist').submit(automl_config)
RunDetails(remote_run).show()
Once more, the Jupyter widget will help the data scientist monitor how the run is progressing.

And the user can inspect the metrics of each individual model that was produced.

For more details on automated machine learning, please visit this article as well as this blog post.
There are many more improvements in this Azure Machine Learning service Public Preview Refresh, and we can’t wait for you to use them. We are confident they will help you be more productive and have more fun building, training and tuning your machine learning models. Read more about a broader overview of the changes in this refresh and visit the Getting started guide to start building your own models using Azure Machine Learning.
Source: Azure Blog Feed