How Skype modernized its backend infrastructure using Azure Cosmos DB – Part 3
This is a three-part blog post series about how organizations are using Azure Cosmos DB to meet real world needs, and the difference it’s making to them. In part 1, we explored the challenges Skype faced that led them to take action. In part 2, we examined how Skype implemented Azure Cosmos DB to modernize its backend infrastructure. In this post (part 3 of 3), we cover the outcomes resulting from those efforts.
Note: Comments in italics/parenthesis are the author's.
The outcomes
Improved throughout, latency, scalability, and more
Using Azure Cosmos DB, Skype replaced three monolithic, geographically isolated data stores with a single, globally distributed user data service that delivers better throughput, lower latencies, and improved availability. The new PCS service can elastically scale on demand to handle to handle future growth, and gives the Skype team ownership of its data without the burden of maintaining its own infrastructure—all at less than half what it cost to maintain the old PCS system. Development of the solution was fast and straightforward thanks to the extensive functionality provided by Azure Cosmos DB and the fact that it’s a fully-hosted service.
Better throughout and lower latencies
Compared to the old solution, the new PCS service is delivering improved throughput and lower latency—in turn enabling the Skype team to easily meet all its SLAs. “Easy geographic distribution, as enabled by Azure Cosmos DB, was a key enabler in making all this possible,” says Kaduk. “For example, by enabling us to put data closer to where its users are, in Europe, we’ve been able to significantly reduce the time required for the permission service that’s used to setup a call—and meet our overall one-second SLA for that task.”
Higher availability
The new PCS service is supporting its workload without timeouts, deadlocks, or quality-of-service degradation—meaning that users are no longer inconvenienced with bad data or having to wait. And because the service runs on Azure Cosmos DB, the Skype team no longer needs to worry about the availability of the underlying infrastructure upon which its new PCS service runs.
“Azure Cosmos DB provides a 99.999 percent read availability SLA for all multiregion accounts, with built-in helps protect against the unlikely event of a regional outage,” says Kaduk. “We can prioritize failover order for our multiregion accounts and can even manually trigger failover to test the end-to-end availability of our app—all with guaranteed zero data-loss.”
Elastic scalability
With Azure Cosmos DB, the Skype team can independently and elastically scale storage and throughput at any time, across the globe. All physical partition management required to scale is fully managed by Azure Cosmos DB and is transparent to the Skype team. Azure Cosmos DB handles the distribution of data across physical and logical partitions and the routing of query requests to the right partition—all without compromising availability, consistency, latency, or throughput. All this enables the team to pay for only the storage and throughput it needs today, and to avoid having to invest any time, energy, or money in spare capacity before it’s needed.
“The ability of Azure Cosmos DB to scale is obvious,” says Kaduk. “We planned for 100 terabytes of data 18 months ago and are already at 140 terabytes, with no major issues handling that growth.
Full ownership of data – with zero maintenance and administration
Because Azure Cosmos DB is a fully managed Microsoft Azure service, the Skype team doesn’t need to worry about day-to-day administration, deploy and configure software, or deal with upgrades. Every database is automatically backed up, protected against regional failures, and encrypted, so you the team doesn’t need to worry about those things either—leaving it with more time to focus on delivering new customer value.
“One of the great things about our new PCS service is that we fully own the data store, whereas we didn’t before,” says Kaduk. “In the past, when Skype was first acquired by Microsoft, we had a team that maintained our databases. We didn’t want to continue maintaining them, so we handed them off to a central team. Today, that same user data is back under our full control and we’re still not burdened with day-to-day maintenance—it’s really the best of both worlds.”
Lower costs
Although Kaduk’s team wasn’t paying to maintain the old PCS databases, he knows what that used to cost—and says that the monthly bill for the new solution running on Azure Cosmos DB is much lower. “Our new PCS data store is about 40 percent less expensive than the old one was,” he states. “We pay that cost ourselves today, but, given all the benefits, it’s well worth it.”
Rapid, straightforward implementation
All in all, Kaduk feels the migration to Azure Cosmos DB was “pretty simple and straightforward.” Development began in May 2017, and by October 2017, all development was complete and the team began migrating all 4 billion Skype users to the new solution. The team consisted of eight developers, one program manager, and one manager.
“We had no prior experience with Azure Cosmos DB, but it was pretty easy to come up to speed,” he states. “Even with a few lessons learned, we did it all in six months, which is pretty impressive for a project of this scale. One reason for our rapid success was that we didn’t have to worry about deploying any physical infrastructure. Azure Cosmos DB also gave us a schema-free document database with both SQL syntax and change feed streaming capabilities built-in, all under strict SLAs. This greatly simplified our architecture and enabled us to meet all our requirements in a minimum amount of time.”
Lessons learned
Looking back at the project, Kaduk recalls several “lessons learned.” These include:
- Use direct mode for better performance – How a client connects to Azure Cosmos DB has important performance implications, especially with respect to observed client side latency. The team began by using the default Gateway Mode connection policy, but switched to a Direct Mode connection policy because it delivers better performance.
- Learn how to write and handle stored procedures – With Azure Cosmos DB, transactions can only be implemented using stored procedures—pieces of application logic that are written in JavaScript that are registered and executed against a collection as a single transaction. (In Azure Cosmos DB, JavaScript is hosted in the same memory space as the database. Hence, requests made within stored procedures execute in the same scope of a database session, which enables Azure Cosmos DB to guarantee ACID for all operations that are part of a single stored procedure.)
- Pay attention to query design – With Azure Cosmos DB, queries have a large impact in terms of RU consumption. Developers didn’t pay much attention to query design at first, but soon found that RU costs were higher than desired. This led to an increased focus on optimizing query design, such as using point document reads wherever possible and optimizing the query selections per API.
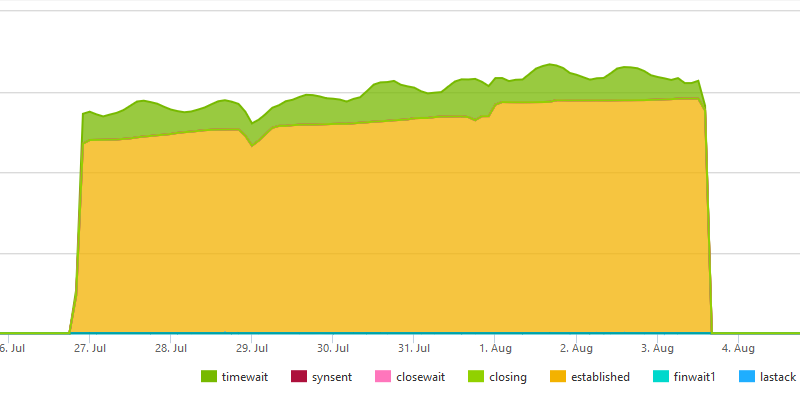
- Use the Azure Cosmos DB SDK 2.x to optimize connection usage – Within Azure Cosmos DB, the data stored in each region is distributed across tens of thousands of physical partitions. To serve reads and writes, the Azure Cosmos DB client SDK must establish a connection with the physical node hosting the partition. The team started by using the Azure Cosmos DB SDK 1.x, but found that its lack of support for connection multiplexing led to excessive connection establishment and closing rates. Switching to the Azure Cosmos DB SDK 2.x, which supports connection multiplexing, helped solve the problem —and also helped mitigate SNAT port exhaustion issues.
The following diagram shows connection status and time_waits when using SDK 1.x.

And the following shows the same after the move to SDK 2.x.

Source: Azure Blog Feed