Advancing failure prediction and mitigation—introducing Narya
"This post continues our Advancing Reliability series highlighting initiatives underway to constantly improve the reliability of the Azure platform. In 2018 we shared steps we're taking to improve virtual machine (VM) resiliency using live migration. In 2019 we shared how we're further improving virtual machine resiliency with Project Tardigrade, which identifies host failures and recovers from them through memory-preserving soft kernel reboots. In 2020 we shared our AIOps vision for improving service quality using artificial intelligence. Today, we wanted to provide an update on how these efforts are evolving by introducing Project Narya, an end-to-end prediction, and mitigation service. As I shared at Microsoft Ignite last week, Narya has become an important part of the intelligent infrastructure of Azure. The post that follows was written by Jeffrey He, a Program Manager from our Azure Compute team."—Mark Russinovich, CTO, Azure
This post includes contributions from Principal Data Scientist Manager Yingnong Dang and Senior Data Scientists Sebastien Levy, Randolph Yao, and Youjiang Wu.
Project Narya is a holistic, end-to-end prediction and mitigation service—named after the "ring of fire" from Lord of the Rings, known to resist the weariness of time. Narya is designed not only to predict and mitigate Azure host failures but also to measure the impact of its mitigation actions and to use an automatic feedback loop to intelligently adjust its mitigation strategy. It leverages our Resource Central platform, a general machine learning and prediction-serving system that we have deployed to all Azure compute clusters worldwide. Narya has been running in production for over a year and, on average, has reduced virtual machine interruptions by 26 percent—helping to run your Azure workloads more smoothly. This blog post provides an overview of this Narya framework, for more details refer to our "Predictive and Adaptive Failure Mitigation to Avert Production Cloud VM Interruptions" paper at the 14th USENIX Symposium on Operating Systems Design and Implementation (OSDI 2020).
How did we approach this before Narya?
In the past, we used machine learning to inform our failure predictions, then selected the mitigation action statically based on the failure predicted. For example, if a piece of hardware was determined to be "at-risk" then we would notify customers running workloads on it that we have detected degraded hardware through in-virtual machine notifications. We would also always perform this set of steps:
- Block new allocations on the node.
- Migrate off as many of the virtual machines as possible on the fly (using live migration).
- Wait several days for short-lived virtual machines to be stopped organically or re-deployed by customers.
- Migrate off the remaining virtual machines by disconnecting the virtual machines and moving them to healthy nodes.
- Bring the node out of production and run internal diagnostics to determine repair action.
Although this approach worked well, we saw several opportunities to improve in certain scenarios. For instance, some failures may be too severe (such as damaged disks) for us to wait days for virtual machines to be stopped or re-deployed. At other times, an "at-risk" prediction might be more minor or even a false positive. In these cases, forced migration would cause unnecessary customer impact, and instead, it would be better to continue monitoring further signals and re-evaluate the node after a given period. Ultimately, we concluded that to truly design the best system for our customers, we needed not only to be more flexible in how we responded to our predictions, but we also needed to measure the exact customer impact of our actions for every different scenario.
How do we approach this now, with Narya?
This is where Narya comes in. Rather than having a single pre-determined mitigation action for an "at-risk" prediction, Narya considers many possible mitigation actions. For a given set of predictions, Narya uses either an online A/B testing framework or a reinforcement learning framework to determine the best possible response.
Phase 1: Failure prediction
Narya starts by using fleet telemetry to predict potential host failures due to hardware faults. We can produce accurate predictions by using a mix of both domain-expert, knowledge-based predictive rules, and a machine learning-based method.
An example of a domain-expert predictive rule is if a CPU Internal Error (IERR) occurs twice within n days (for example, n = 30), this indicates that the node will likely fail again soon. Narya currently uses several dozen domain-expert predictive rules derived from data-driven methods.
Narya also incorporates a machine learning model, which is helpful because it analyzes more signals and patterns over a larger time frame than the predictive rules—allowing us to predict failures earlier. This builds on our prior failure prediction work but, rather than focusing on failures of individual components, this model now reviews overall host health with respect to real customer impact. Since 2018, we have also expanded the kinds of incoming signals and have improved signal quality. As a result, we have reduced the number of false positives and negatives, ultimately improving the effectiveness of this failure prediction step.
Phase 2: Deciding and applying mitigation actions
Rather than having one fixed mitigation strategy, we created a selection of mitigation actions for Narya to consider. Each mitigation action can be considered as a composite of many smaller steps, including:
- Marking the node as unallocatable.
- Live migrating the virtual machines to other nodes.
- Soft rebooting the kernel while preserving memory, which minimizes interruptions to customer workloads which experience only a short pause.
- Deprioritizing allocations on the node.
- And more.
For example, one mitigation action might be to mark the node unallocatable, then attempt a memory-preserving kernel soft reboot, and mark allocatable again if successful. If unsuccessful, implement a live migration and send the node to diagnostics, where we run tests to determine whether the hardware is degraded. If it is, then we send the node to repair and replace the hardware. Overall, this gives us far more flexibility to handle different scenarios with different mitigations, improving overall Azure host resilience.
To respond to "at-risk" predictions in a much more flexible manner, Narya uses an online A/B testing framework and a reinforcement learning (RL) framework to continuously optimize the mitigation action for minimal virtual machine interruptions.
A/B testing framework
When Narya conducts A/B testing, it selects different mitigation actions, compares them to a control group with no action taken, and gathers all the data to determine which mitigation actions are best for which scenarios. From then onwards, for this given set of failure predictions, it continuously selects the best actions—helping to reduce virtual machine reboots, ensure more available capacity, and maintain the best performance.
Reinforcement learning (RL) framework
When Narya uses reinforcement learning, it learns how to maximize the overall customer experience by exploring different actions over time, weighing the most recent actions the most heavily. Reinforcement learning is different from A/B testing in that it automatically learns to avoid less optimal actions by continuously balancing between using the most optimal actions and exploring new ones.
Phase 3: Observe customer impact and retrain models
Finally, after mitigation actions are taken, new data can be gathered. We now have a measure of the most up-to-date customer impact data, which we use to continually improve our models at every step of the Narya framework. Narya makes sure to do this automatically—the data not only helps us to update the domain-expert rules and the machine learning models in the failure prediction step, but also informs better mitigation action policy in the decision step.

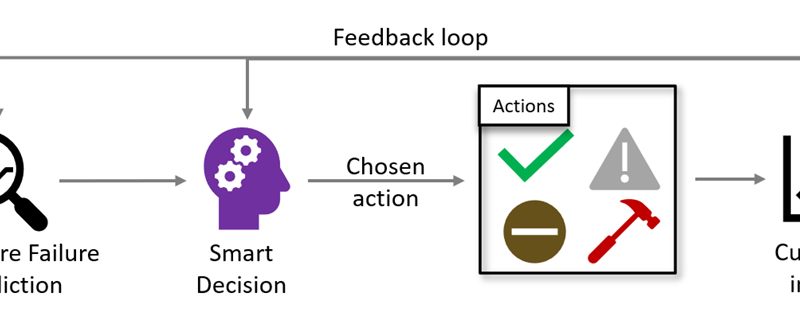
Figure 1: Narya starts with a hardware failure prediction, makes a smart decision on how to respond, implements the response, then measures the customer impact and incorporates it via a feedback loop.
Narya in action: an example
The following is a real example in which Narya helped to protect real customer workloads:
- T0 20:15:31, Narya predicted the node had a high probability of failure due to disk issues.
- T0 20:32:01, Narya selected the mitigation action: "Mark the node as unallocatable for three days, attempt a live migration, and after all the virtual machines have been migrated or if the host fails, send the node to diagnostics."
- T0 20:32:11, the node was marked unallocatable, and a live migration was triggered.
- T0 20:47:22 – 00:11:55, nine virtual machines eligible for live migration were live migrated off the node successfully.
- T1 19:14:01, the node went unhealthy, and 15 virtual machines still on the node were rebooted.
- T1 19:55:07, the node sent to diagnostics after entering fault state.
- T2 00:14:12, the disk stress test failed.
- T3 00:19:56, the disk was replaced.
In this real-world example, Narya prevented nine virtual machine reboots and prevented further customer pain by ensuring that no new workloads were allocated to the node that was expected to fail soon. In addition, the broken node was immediately sent for repair, and there were no repeated virtual machine reboots as we already anticipated the issue. While this example is relatively simple, the main purpose is to illustrate that Narya evaluated the situation and smartly selected this mitigation action for this situation. In other scenarios, the mitigation action might involve marking the node unallocatable for a different number of days, trying a soft kernel reboot instead of a live migration, or deprioritizing allocations rather than fully marking the node as unallocatable. Narya is built to respond much more flexibly to different "at-risk" predictions, to best improve the overall customer experience.
What makes Narya different?
- Data-driven action selection: Instead of making our best guess for the mitigation action, we are now testing and measuring the effects of each mitigation action, using data to determine the true impact of each mitigation action selected.
- Dynamic wherever possible: As opposed to having static mitigation assignments, Narya now continuously ensures that the best mitigation action is selected even as the system changes via software updates, hardware updates, or customer workload changes, etc. For example, perhaps there is a static assignment where a predicted failure caused by a drop in CPU frequency leads us to perform a live migration. While this might be a defense mechanism to indicate an imminent failure, a recent update to the Azure platform might have the system intentionally adjust CPU frequency to rebalance power consumption, meaning a drop in CPU frequency might not necessarily mean we should perform a live migration. With a static assignment, we would accidentally apply actions that end up doing harm, as we mistakenly avoid using healthy nodes. With Narya, we will notice from A/B testing and reinforcement learning that, for this specific scenario, live migration is no longer the optimal mitigation action.
- Flexible mitigation actions: In the past, only one given mitigation action could be prescribed for a given set of symptoms. However, with multi-tenancy and diverse customer workloads, even with expert-domain knowledge, it was difficult to determine the best mitigation ahead of time. With Narya, we can now configure as many mitigation actions as we would like and allow Narya to automatically test and select the action items best suited for different failure predictions. Finally, because we have smart safety mechanisms in place, we can also be confident that Narya's mitigation action chains will prevent any dead-locks that might lead to indefinite blocking.
Going forward
Moving forward, we hope to improve Narya to make Azure even more resilient and reliable. Specifically, we plan to:
- Incorporate more prediction scenarios: We plan to develop more advanced hardware failure prediction techniques covering more hardware failure types. We also plan to incorporate more software scenarios into this prediction step.
- Incorporating more mitigation actions: By building additional mitigation actions, we will be able to add more flexibility into how Narya can respond to a broad scope of failure predictions.
- Making the decision smarter: Finally, we plan to improve Narya by adding more nuance into the "smart decision" step, where we decide on the best mitigation action. For example, we can look at what workloads are running on a given node, incorporate that information into the "smart decision" step, and time our mitigation action in a manner that minimizes interruptions.
For a more detailed explanation of the Narya framework, check out our "Predictive and Adaptive Failure Mitigation to Avert Production Cloud VM Interruptions" paper at the 14th USENIX Symposium on Operating Systems Design and Implementation (OSDI 2020).
Source: Azure Blog Feed