Advancing safe deployment with AIOps—introducing Gandalf
“Changes to Azure services and the Azure platform itself are both inevitable and beneficial, to ensure continuous delivery of updates, new features, and security enhancements. However, change is also a primary cause of service regressions that can contribute towards reliability issues—for hyperscale cloud providers, indeed for any IT service provider. As such, it is critical to catch any such problems as early as possible during the development and deployment rollout, to minimize any impact on the customer experience. As part of our ongoing Advancing Reliability blog series, today I’ve asked Principal Program Manager Jian Zhang from our AIOps team to introduce how we’re increasingly leveraging machine learning to de-risk these changes, ultimately to improve the reliability of Azure.”—Mark Russinovich, CTO, Azure
This post includes contributions from Principal Data Scientists Ken Hsieh and Ze Li, Principal Data Scientist Manager Yingnong Dang, and Partner Group Software Engineering Manager Murali Chintalapati.
In our earlier blog post “Advancing safe deployment practices” Cristina del Amo Casado described how we release changes to production, for both code and configuration changes, across the Azure platform. The processes consist of delivering changes progressively, with phases that incorporate enough bake time to allow detection at a small scale for most regressions missed during testing.
The continuous monitoring of health metrics is a fundamental part of this process, and this is where AIOps plays a critical role—it allows the detection of anomalies to trigger alerts and the automation of correcting actions such as stopping the deployment or initiating rollbacks.
In the post that follows, we introduce how AI and machine learning are used to empower DevOps engineers, monitor the Azure deployment process at scale, detect issues early, and make rollout or rollback decisions based on impact scope and severity.
Why AIOps for safe deployment
As defined by Gartner, AIOps enhances IT operations through insights that combine big data, machine learning, and visualization to automate IT operations processes, including event correlation, anomaly detection, and causality determination. In our earlier post, "Advancing Azure service quality with artificial intelligence: AIOps," we shared our vision and some of the ways in which we are already using AIOps in practice, including around safe deployment. AIOps is well suited to catching failures during deployment rollout, particularly because of the complexities of cross-service dependencies, the scale of hyperscale cloud services, and the variety of different customer scenarios supported.
Phased rollouts and enriched health signals are used to facilitate monitoring and decision making in the deployment process, but the volume of signals and level of complexity involved in deployment decision making exceeds what any human could reasonably reason over, across thousands of ever-evolving service components, spanning more than 200 datacenters in more than 60 regions. Some latent issues won’t manifest for several days after their deployment, and global issues that span different clusters but manifest only minutely in any individual cluster are hard to detect with just a local watchdog. While loose coupling allows most service components to be deployed independently, their deployments could have intricate impacts on each other. For example, a simple change in an upstream service could potentially impact a downstream service if it breaks the contract of API calls between the two services.
These challenges call for automated monitoring, anomaly detection, and rollout impact assessment solutions to facilitate deployment decisions at velocity.

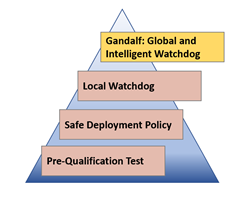
Figure 1: Gandalf safe deployment
Gandalf safe deployment service: An AIOps solution
Rising to the challenge described above, the Azure Compute Insights team developed the “Gandalf” safe deployment service—an end-to-end, continuous monitoring system for safe deployment. We consider this part of the Gandalf AIOps solution suite, which includes a few other intelligent monitoring services. The code name Gandalf was inspired by the protagonist from The Lord of the Rings, as shown in Figure 1, it serves as a global watchdog, which makes intelligent deployment decisions based on signals collected. It works in tandem with local watchdogs, safe deployment policies, and pre-qualification tests, all to ensure deployment safety and velocity.
As illustrated in Figure 2, the Gandalf system monitors rich and representative signals from Azure, performs anomaly detection and correlation, then derives insights to support deployment decision making and actions.

Figure 2: Gandalf system overview
Data sources
Gandalf monitors signals across performance, failures, and events as described below. It pre-processes the data to structure them around a unified data schema to support downstream data analytics. It also leverages a few other analytics services within Azure for health signals, including our Virtual Machine failure categorization service and near real-time failure attribution processing service. Signal registration with Gandalf is required when any new service components are onboarded, to ensure complete coverage.
- Performance data: Gandalf monitors performance counters, CPU usage, memory usage, and more – all for a high-level view of performance and resource consumption patterns of hosted services.
- Failure signals: Gandalf monitors both the hosting environment of customer’s virtual machines (data plane) and tenant-level services (control plane). For the data plane, it monitors failure signals such as OS crashes, node faults, and reboots to evaluate the health of the VM’s hosting environment. At the same time, it monitors failure signals of the control plane like API call failures, to evaluate the health of tenant-level services.
- Update events: In addition to telemetry data collected, Gandalf also keeps its finger on the pulse of deployment events, which report deployment progress and issues.
Detection, correlation, and decision
Gandalf evaluates the impact scope of the deployment—for example, the number of impacted nodes, clusters, and customers—to make a go/no-go decision using decision criteria that are trained dynamically. To balance speed and coverage, Gandalf utilizes an architecture with both streaming and batch analysis engines.

Figure 3: Gandalf Anomaly Detection and Correlation Mode
Figure 3 shows an overview of the Gandalf Machine Learning (ML) model. It consists of two parts—anomaly detection and correlation process (to identify suspicious deployments) and a decision process (to evaluate customer impact).
Anomaly detection and correlation process
To ensure precise detection, Gandalf derives fault signatures from input signals, which can be used to uniquely identify the failure. Then, it detects based on the occurrence of the fault signature.
In large-scale cloud systems like Azure, simple threshold-based detection is not practical both because of the dynamic nature of the systems and workloads hosted and because of the sheer volume of fault signatures. Gandalf applies machine learning techniques to estimate baseline settings based on historical data automatically and can adapt the setting through training as needed.
When Gandalf detects an anomaly, it correlates the observed failure with deployment events and evaluates its impact scope. This helps to filter out failures caused by non-deployment reasons such as random firmware issues.
Since multiple system components are often deployed concurrently, a vote-veto mechanism is used to establish the relationship between the faults and the rollout components. In addition, temporal and spatial correlations are used to identify the components at fault. Fault age, which measures the time between rollout and detection of fault signature, is considered to allow more focus on new rollouts than old ones since newly observed faults are less likely to be triggered by the old rollout.
In this way, Gandalf can detect an anomaly that would lead to potential regressions in the customer experience early in the process—before it generates widespread customer impact. For more detail, refer to our published paper “Gandalf: An Intelligent, end-to-end analytics service for safe deployment in large-scale cloud infrastructure.”
Decision process
Finally, Gandalf evaluates the impact scope of the deployment such as the number of impacted clusters/nodes/customers, and ultimately makes a "go/no-go" decision. It’s worth mentioning that Gandalf is designed to allow developers to customize signals’ weight assignment based on their experience. In this way, it can incorporate domain knowledge from human experts to complement its machine learning solutions.
Result orchestration
To balance speed and coverage, Gandalf utilizes both streaming and batch processing of incoming signals. Streaming processing consumes data from Azure Data Explorer, a cloud storage solution supporting analytics with fast speed. Streaming processing is used to process fault signals that happen 1 hour before and after each deployment in each node and runs lightweight analysis algorithms for rapid response.
Batch processing consumes data from Cosmos, a Hadoop-like file system that supports extremely large volumes of data. It’s used to analyze faults over a larger time window (generally a 30-day period) with advanced algorithms.
Both stream and batch processing are performed incrementally with five-minute intervals. In general, the incoming telemetry signals of Gandalf are both streamed into Kusto and stored into Cosmos hourly/daily. With the same data source, occasionally there could be inconsistent results from the processing pipeline. This is by design since batch processing makes more informed decisions and covers latent issues that the fast/streaming process cannot detect.
Deployment experience transformation
The Gandalf system is now well integrated into our DevOps workflow within Azure and has been widely adopted for deployment health monitoring across the entire fleet. It not only helps to prevent bad rollouts as quickly as possible but has also transformed the engineers’ and release managers’ experience in deploying software changes—from looking for scattered evidence to using a single source of truth, from ad-hoc diagnoses to using interactive troubleshooting—and in so doing, many of the engineers who interact with Gandalf have had their opinions on it transformed as well, evolving from skeptics to advocates.
In many Azure services, Gandalf has become a default baseline for all release validations, and it’s exciting to hear how much our on-call engineers trust Gandalf.
Summary
In this post, we have introduced the Gandalf safe deployment service, an intelligent, end-to-end analytics service for the safe deployment of Azure services. Through state-of-the-art anomaly detection, special and temporal correlation, and result orchestration, the Gandalf safe deployment service enables DevOps engineers to make go/no-go decisions accurately, and with the velocity needed by hyper-scale cloud platforms like Azure.
We will continue to invest in applying AI- and machine learning-based technologies to improve cloud service management, ultimately to continue improving the customer experience. Look for us to share more about our AIOps solutions, including pre-production analytics to further help us push quality to the left.
Source: Azure Blog Feed