The emerging big data architectural pattern
Why lambda?
Lambda architecture is a popular pattern in building Big Data pipelines. It is designed to handle massive quantities of data by taking advantage of both a batch layer (also called cold layer) and a stream-processing layer (also called hot or speed layer).
The following are some of the reasons that have led to the popularity and success of the lambda architecture, particularly in big data processing pipelines.
Speed and business challenges
The ability to process data at high speed in a streaming context is necessary for operational needs, such as transaction processing and real-time reporting. Some examples are fault/fraud detection, connected/smart cars/factory/hospitals/city, sentiment analysis, inventory control, network/security monitoring, and many more.
Typically, batch processing, involving massive amounts of data, and related correlation and aggregation is important for business reporting. This is to understand how the business is performing, what the trends are, and what corrective or additive measure can be executed to improve business or customer experience.
Product challenges
One of the triggers that lead to the very existence of lambda architecture was to make the most of the technology and tool set available. Existing batch processing systems, such as data warehouse, data lake, Spark/Hadoop, and more, could deal with petabyte scale data operations easily but couldn’t do it fast enough that was warranted by the operational needs.
Similarly, very fast layers such as cache databases, NoSQL, streaming technology allows fast operational analytics on smaller data sets but cannot do massive scale correlation and aggregation and other analytics operations (such as Online Analytical Processing) like a batch system can.
The skills challenge
Additionally, in the market you will find people who are highly skilled in batch systems, and often they do not have the same depth of skills in stream processing, and vice versa.
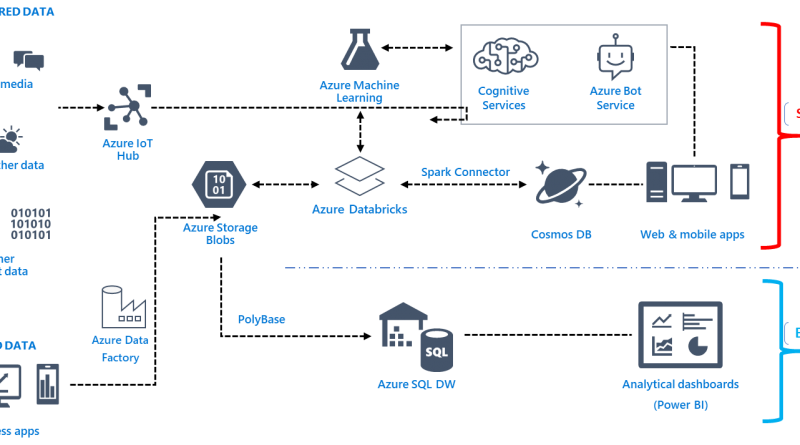
Lambda on Azure
The following is one of the many representative Lambda architecture on Azure for building Big Data pipelines.

Figure 1: Lambda architecture for big data processing represented by Azure products and services. Note, other Azure and (or) ISV solutions can be placed in the mix if needed based on specific requirements.
What problems do lambda solve vs. what problems does it introduce?
As stated in the previous section, lambda architecture resolves some business challenges. Various parts of the business have different needs in terms of speed, level of granularity and mechanism to consume data. It also resolves the challenge of the choice of technology, by using the best of the speed layer and batch layer together, and not stretching one product to do both which it isn’t comfortable in doing. Finally, it ensures people with skills dealing with transaction and speed layer can work in parallel and together with people with skills in batch processing.
Although immensely successful and widely adopted across many industries and a defacto architectural pattern for big data pipelines, it comes with its own challenges. Here are a few:
-
Transient data silos: Lambda pipelines often creates silos that could may cause some challenges in the business. The reporting at the speed layer that the operations team is dealing with, may be different for the aggregate batch layer that the management teams are working with. Such creases may eventually iron out, but it has the potential of causing some inconsistencies.
- More management overhead: It also increases the number of subsystems, as a result during maintenance time, many needed to be managed and maintained. This could potentially mean one may need bigger teams with deep and wide skill sets.
The emerging big data design pattern
If there was a way that utilized the right mix of technologies that didn’t need a separate speed or batch layer, we could build a system that has only a single layer and allows attributes of both the speed layer and batch layer. With the technological breakthrough at Microsoft, particularly in Azure Cosmos DB, this is now possible.
Azure Cosmos DB is a globally distributed, multi-model database. With Cosmos DB you can independently scale throughput and storage across any number of Azure's geographic regions. It offers throughput, latency, availability, and consistency guarantees with comprehensive service level agreements (SLAs).
Here are some of the key features that renders Cosmos DB as a suitable candidate for implementing the proposed reference architecture where the speed later and the batch layer merges into a single layer.
Cosmos DB change feed
- Most importantly, the key feature that is pivotal in building this emerging big data architectural pattern is the Cosmos DB change feed. Change feed support works by listening to an Azure Cosmos DB collection for any changes. Then, it outputs the sorted list of documents that were changed in the order in which they were modified. The changes are persisted, can be processed asynchronously and incrementally, and the output can be distributed across one or more consumers for parallel processing.
Features for speed/hot layer
- Azure Cosmos DB’s database engine is fully schema-agnostic – it automatically indexes all the data it ingests without requiring any schema or indexes and serves blazing fast queries.
- Cosmos DB allows you to easily scale database throughput at a per-second granularity, and change it anytime you want.
- You can distribute your data to any number of Azure regions, with the click of a button. This enables you to put your data where your users are, ensuring the lowest possible latency to your customers.
- Azure Cosmos DB guarantees end-to-end low latency at the 99th percentile to its customers. For a typical 1KB item, Cosmos DB guarantees end-to-end latency of reads under 10 ms and indexed writes under 15 ms at the 99th percentile, within the same Azure region. The median latencies are significantly lower (under 5 ms).
Features for batch/cold layer
- You can access your data by using APIs of your choice, like the SQL, MongoDB, Cassandra API, and Table APIs, and graph via the Gremlin API. All APIs are all natively supported.
- You can also scale storage size transparently and automatically to handle your size requirements now and forever.
- Five well-defined, practical, and intuitive consistency models provide a spectrum of strong SQL-like consistency all the way to the relaxed NoSQL-like eventual consistency, and everything in-between.
- Rapidly iterate the schema of your application without worrying about database schema and/or index management.
- Using the features described above, the following will be an implementation of the emerging architectural pattern.
The following is a diagrammatic representation of the emerging big data pipeline that we have been discussing in this blog:

Figure 2: Emerging architectural pattern implemented using Cosmos DB for Big Data pipelines as an evolution of the traditional lambda architecture.
Hence, by leveraging Cosmos DB features, particularly the change feed architecture, this emerging pattern can resolve many of the common use-cases. This in turn, gives all the benefits of the lambda architecture, and resolves some of complexities that lambda introduces. More and more customers adopting this and resulting in a successful community, and success of this new pattern and increased adoption of Azure Cosmos DB.
What’s next?
The following is a list of resources that may help you get started quickly:
- If you haven't already, download the Spark to Azure Cosmos DB connector from the azure-cosmosdb-spark GitHub repository.
- The stream feed from Twitter to CosmosDB, which is the mechanism to push new data into Azure Cosmos DB.
- As well with the Cosmos DB Time-to-Live (TTL) feature, you can configure your documents to be automatically deleted after a set duration. For more information on the Azure Cosmos DB TTL feature, see Expire data in Azure Cosmos DB collections automatically with time to live.
- Azure Cosmos DB BulkExecutor library overview.
- Hands on labs using Azure Services to build Azure IoT End to End Solutions connecting real and simulated devices to Azure IoT Hub.
- Perform graph analytics by using Spark and Apache TinkerPop Gremlin.
- Connect to Azure Cosmos DB using BI analytics tools with the ODBC driver.
Source: Azure Blog Feed