A technical overview of Azure Databricks
This blog post was co-authored by Peter Carlin, Distinguished Engineer, Database Systems and Matei Zaharia, co-founder and Chief Technologist, Databricks.
Today at Microsoft Connect(); we introduced Azure Databricks, an exciting new service in preview that brings together the best of the Apache Spark analytics platform and Azure cloud. As a close partnership between Databricks and Microsoft, Azure Databricks brings unique benefits not present in other cloud platforms. This blog post introduces the technology and new capabilities available for data scientists, data engineers, and business decision-makers using the power of Databricks on Azure.
Apache Spark + Databricks + enterprise cloud = Azure Databricks
Once you manage data at scale in the cloud, you open up massive possibilities for predictive analytics, AI, and real-time applications. Over the past five years, the platform of choice for building these applications has been Apache Spark, with a massive community at thousands of enterprises worldwide, Spark makes it possible to run powerful analytics algorithms at scale and in real time to drive business insights. However, managing and deploying Spark at scale has remained challenging, especially for enterprise use cases with large numbers of users and strong security requirements.
Enter Databricks. Founded by the team that started the Spark project in 2013, Databricks provides an end-to-end, managed Apache Spark platform optimized for the cloud. Featuring one-click deployment, autoscaling, and an optimized Databricks Runtime that can improve the performance of Spark jobs in the cloud by 10-100x, Databricks makes it simple and cost-efficient to run large-scale Spark workloads. Moreover, Databricks includes an interactive notebook environment, monitoring tools, and security controls that make it easy to leverage Spark in enterprises with thousands of users.
In Azure Databricks, we have gone one step beyond the base Databricks platform by integrating closely with Azure services through collaboration between Databricks and Microsoft. Azure Databricks features optimized connectors to Azure storage platforms (e.g. Data Lake and Blob Storage) for the fastest possible data access, and one-click management directly from the Azure console. This is the first time that an Apache Spark platform provider has partnered closely with a cloud provider to optimize data analytics workloads from the ground up.
Benefits for data engineers and data scientists
Why is Azure Databricks so useful for data scientists and engineers? Let’s look at some ways:
Optimized environment
Azure Databricks is optimized from the ground up for performance and cost-efficiency in the cloud. The Databricks Runtime adds several key capabilities to Apache Spark workloads that can increase performance and reduce costs by as much as 10-100x when running on Azure, including:
- High-speed connectors to Azure storage services, such as Azure Blob Store and Azure Data Lake, developed together with the Microsoft teams behind these services.
- Auto-scaling and auto-termination for Spark clusters to automatically minimize costs.
- Performance optimizations including caching, indexing, and advanced query optimization, which can improve performance by as much as 10-100x over traditional Apache Spark deployments in cloud or on-premise environments.
Seamless collaboration
Remember the jump in productivity when documents became truly multi-editable? Why can’t we have that for data engineering and data science? Azure Databricks brings exactly that. Notebooks on Databricks are live and shared, with real-time collaboration, so that everyone in your organization can work with your data. Dashboards enable business users to call an existing job with new parameters. Also, Databricks integrates closely with PowerBI for interactive visualization. All this is possible because Azure Databricks is backed by Azure Database and other technologies that enable highly concurrent access, fast performance, and geo-replication.
Easy to use
Azure Databricks comes packaged with interactive notebooks that let you connect to common data sources, run machine learning algorithms, and learn the basics of Apache Spark to get started quickly. It also features an integrated debugging environment to let you analyze the progress of your Spark jobs from within interactive notebooks, and powerful tools to analyze past jobs. Finally, other common analytics libraries, such as the Python and R data science stacks, are preinstalled so that you can use them with Spark to derive insights. We really believe that big data can become 10x easier to use, and we are continuing the philosophy started in Apache Spark to provide a unified, end-to-end platform.
Architecture of Azure Databricks
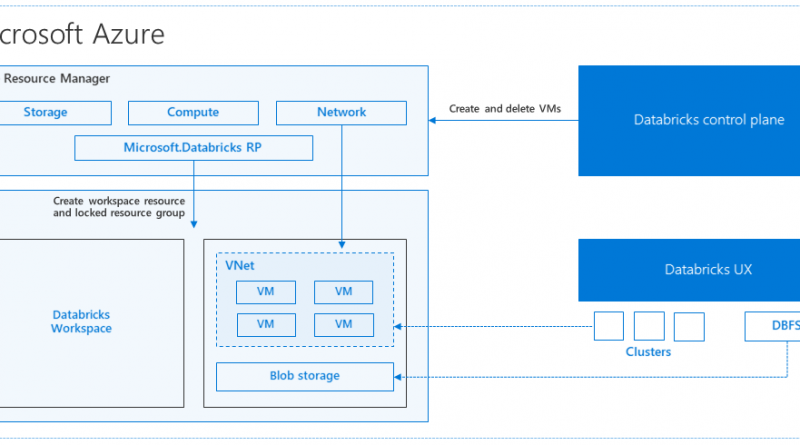
So how is Azure Databricks put together? At a high level, the service launches and manages worker nodes in each Azure customer's subscription, letting customers leverage existing management tools within their account.
Specifically, when a customer launches a cluster via Databricks, a "Databricks appliance" is deployed as an Azure resource in the customer's subscription. The customer specifies the types of VMs to use and how many, but Databricks manages all other aspects. In addition to this appliance, a managed resource group is deployed into the customer's subscription that we populate with a VNet, a security group, and a storage account. These are concepts Azure users are familiar with. Once these services are ready, users can manage the Databricks cluster through the Azure Databricks UI or through features such as autoscaling. All metadata, such as scheduled jobs, is stored in an Azure Database with geo-replication for fault tolerance.

For users, this design means two things. First, they can easily connect Azure Databricks to any storage resource in their account, e.g., an existing Blob Store subscription or Data Lake. Second, Databricks is managed centrally from the Azure control center, requiring no additional setup.
Total Azure integration
We are integrating Azure Databricks closely with all features of the Azure platform in order to provide the best of the platform to users. Here are some pieces we’ve done so far:
- Diversity of VM types: Customers can use all existing VMs including F-series for machine learning scenarios, M-series for massive memory scenarios, D-series for general purpose, etc.
- Security and Privacy: In Azure, ownership and control of data is with the customer. We have built Azure Databricks to adhere to these standards. We aim for Azure Databricks to provide all the compliance certifications that the rest of Azure adheres to.
- Flexibility in network topology: Customers have a diversity of network infrastructure needs. Azure Databricks supports deployments in customer VNETs, which can control which sources and sinks can be accessed and how they are accessed.
- Azure Storage and Azure Data Lake integration: These storage services are exposed to Databricks users via DBFS to provide caching and optimized analysis over existing data.
- Azure Power BI: Users can connect Power BI directly to their Databricks clusters using JDBC in order to query data interactively at massive scale using familiar tools.
- Azure Active Directory provide controls of access to resources and is already in use in most enterprises. Azure Databricks workspaces deploy in customer subscriptions, so naturally AAD can be used to control access to sources, results, and jobs.
- Azure SQL Data Warehouse, Azure SQL DB, and Azure CosmosDB: Azure Databricks easily and efficiently uploads results into these services for further analysis and real-time serving, making it simple to build end-to-end data architectures on Azure.
In addition to all the integration you can see, we have worked hard to integrate in ways that you can’t see – but can see the benefits of.
- Internally, we use Azure Container Services to run the Azure Databricks control-plane and data-planes via containers.
- Accelerated Networking provides the fastest virtualized network infrastructure in the cloud. Azure Databricks utilizes this to further improve Spark performance.
- The latest generation of Azure hardware (Dv3 VMs), with NvMe SSDs capable of blazing 100us latency on IO. These make Databricks I/O performance even better.
We are just scratching the surface though! As the service becomes generally available and moves beyond that, we expect to add continued integrations with other upcoming Azure services.
Conclusion
We are very excited to partner together to bring you Azure Databricks. For the first time, a leading cloud provider and leading analytics system provider have partnered to build a cloud analytics platform optimized from the ground up – from Azure's storage and network infrastructure all the way to Databricks's runtime for Apache Spark. We believe that Azure Databricks will greatly simplify building enterprise-grade production data applications, and we would love to hear your feedback as the service rolls out.
Source: Azure Blog Feed