Sync SQL data in large scale using Azure SQL Data Sync
Azure SQL Data Sync allows users to synchronize data between Azure SQL Databases and SQL Server databases in one-direction or bi-direction. This feature was first introduced in 2012. By that time, people didn't host a lot of large databases in Azure. Some size limitations were applied when we built the data sync service, including up to 30 databases (five on-premises SQL Server databases) in a single sync group, and up to 500 tables in any database in a sync group.
Today, there are more than two million Azure SQL Databases and the maximum database size is 4TB. But those limitations of data sync are still there. It is mainly because that syncing data is a size of data operation. Without an architectural change, we can’t ensure the service can sustain the heavy load when syncing in a large scale. We are working on some improvements in this area. Some of these limitations will be raised or removed in the future. In this article, we are going to show you how to use data sync to sync data between large number of databases and tables, including some best practices and how to temporarily work around database and table limitations.
Sync data between many databases
Large companies and ISVs use data sync to distribute data from a central master database to many client databases. Some customers have hundreds or even thousands of client databases in the whole topology. Users may hit one of the following issues when trying to sync between many databases:
- Hit the 30 databases per sync group limitation.
- Hit the five on-premises SQL Server databases per sync group limitation.
- Since all member databases will sync with the hub database, there’s significant performance impact to workload running in the hub database.
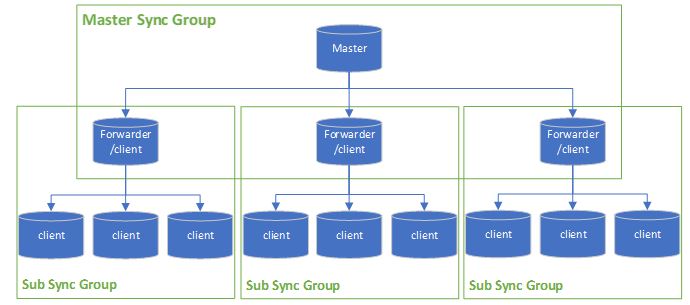
To work around the 30 databases or five on-premises databases per sync group limitation, we suggest you use a multi-level sync architecture. You can create a sync group to sync your master database with several member databases. And those member databases can become the hub databases of the sub sync groups and sync data to other client databases. According to your business and cost requirement, you can use the databases in the middle layers as client databases or dedicated forwarders.

There are benefits from this multi-level sync architecture even you don’t hit the 30 databases per sync group limitation:
- You can group clients based on certain attributes (location, brand…) and use different sync schema and sync frequency.
- You can easily add more clients when your business is growing.
- The forwarders (member databases in the middle layers) can share the sync overhead from the master database.
To make this multi-level sync topology work in your system, you will need a good balance between how many client databases in a single sync group and how many levels in the overall system. The more databases in a single sync group, the higher impact it will add to the overall performance in the hub database. The more levels you have in your system, the longer it takes to have data changes broadcasted to all clients.
When you are adding more member databases to the system, you need to closely monitor the resource usage in the hub databases. If you see consistent high resource usage, you may consider upgrading your database to a higher SLO. Since the hub database is an Azure SQL database, you can upgrade it easily without downtime.
Sync data between databases with many tables
Currently, data sync can only sync between databases with less than 500 tables. You can work around this limitation by creating multiple sync groups using different database users. For example, you want to sync two databases with 900 tables. First, you need to define two different users in the database where you load the sync schema from. Each user can only see 450 (or any number less than 500) tables in the database. Sync setup requires ALTER DATABASE permission which implies CONTROL permission over all tables so you will need to explicitly DENY the permissions on tables which you don’t want a specific user to see, instead of using GRANT. You can find the exact privilege needed for sync initialization in the best practice guidance. Then you can create two sync groups, one for each user. Each sync group will sync 450 tables between these two databases. Since each user can only see less than 500 tables, you will be able to load the schema and create sync groups! After the sync group is created and initialized, we recommend you follow the best practice guidance to update the user permission and make sure they have the minimum privilege for ongoing sync.

Optimize the sync initialization
After the sync group is created, the first time you trigger the sync, it will create all tracking tables and stored procedures and load all data from source to target database. The initial data loading is a size-of-data operation. Initializing sync between large databases could take hours or even days if it is not set up properly. Here are some tips to optimize the initialization performance:
- Data sync will initialize the target tables using bulk insert if the target tables are empty. If you have data on both sides, even if data in source and target databases are identical (data sync won’t know that!), data sync will do a row-by-row comparison and insertion. It could be extremely slow for large tables. To gain the best initialization performance, we recommend you consolidate data in one of your databases and keep the others empty before setting up data sync.
- Currently, the data sync local agent is a 32 bits application. It can only use up to 4GB RAM. When you are trying to initialize large databases, especially when trying to initialize multiple sync groups at the same time, it may run out of memory. If you encountered this issue, we recommend you add part of the tables into the sync group first, initialize with those tables, and then add more tables. Repeat this until all tables are added to the sync group.
- During initialization, the local agent will load data from the database and store it as temp files in your system temp folder. If you are initializing sync group between large databases, you want to make sure your temp folder has enough space before you start the sync. You can change your temp folder to another drive by set the TEMP and TMP environment variables. You will need to restart the sync service after you update the environment variable. You can also add and initialize tables to the sync group in batch. Make sure the temp folder is cleaned up between each batch.
- If you are initializing data from on-premises SQL Server to Azure DB, you can upgrade your Azure DB temporarily before the initialization. You can downgrade the database to the original SLO after the initialization is done. The extra cost will be minimum. If your target database is SQL Server running in a VM, add more resources to the VM will do the same.
Experiment of sync initialization performance
Following is the result of a simple experiment. I created a sync group to sync data from a SQL Server database in Azure VM to an Azure SQL database. The VM and SQL database are in the same Azure region so the impact of network latency could be ignored. It was syncing one table with 11 columns and about 2.1M rows. The total data size is 49.1GB. I did three runs with different source and target database configuration:
In the first run, the target database is S2 (50 DTU), and source database is running in D4S_V3 VM (4 vCPU, 16GB RAM). It takes 50 min to extract data to the temp folder and 471 min to load the data from the temp folder to the target database.
I upgraded the target database to S6 (400 DTU) and the Azure VM to D8S_V3 (8 vCPU, 32GB RAM) for the second run. It reduced the loading time to 98 min! The data extracting surprisingly took longer time in this run. I can’t explain the regression since I didn’t capture the local resource usage during the run. It might be some disk I/O issue. Even though, upgrading the target database to S6 reduced the total initialization time from 521 min to 267 min.
In the third run, I upgraded the target database to S12 (3000 DTU) and used the local SSD as temp folder. It reduced data extract time to 39 min, data loading time to 56 min and the total initialization time to 95 min. It was 5.5 time faster than the first configuration with extra cost of a cup of coffee!
Conclusion
- Upgrade the target database (Azure DB) to higher SLO will help to improve the initialization time significantly with manageable extra cost.
- Upgrade the source database doesn’t help too much since the data extract is an I/O bound operation and 32bits local agent can only use up to 4GB RAM.
- Using attached SSD as temp folder will help on the data extract performance. But the ROI is not as high as upgrading target database. You also need to consider if the temp files can fit into the SSD disk.
| Runs | Target database SLO (Azure DB) | Source database SLO (VM) | Total Initialization time | Data extract time | Data load time |
| 1 | S2 | D4S_V3 | 521 min | 50 min | 471 min |
| 2 | S6 | D8S_V3 | 267 min | *169 min | 98 min |
| 3 | S12 | D8S_V3, Attached SSD | 95 min | 39 min | 56 min |
In this article, we provided some best practices about how to sync data using Azure SQL Data Sync service between many databases and databases with many tables. Please find more information about data sync in the online documentation. More data sync best practice is available at Best Practices for Azure SQL Data Sync.
Source: Azure Blog Feed