
Internet-Scale Deep Learning for Bing Image Search and Ranking
At Bing we are continuously innovating to provide our users with ever better, more accurate, and more beautiful results. We routinely embrace modern advances in multiple domains such as natural language processing, computer vision and AI to provide the best experience at internet scale across billions of queries and images. Recently we talked about how semantic vectors helped improve Bing Web Search. Today we want to share how end-to-end deployment of semantic, vector-based deep learning techniques in our image search stack makes Bing even more intelligent, and how it enables us to find more satisfying results to complex image search queries.
Today when a user issues a query such as 'pencil erasers that look like tools,’ Bing doesn't just retrieve images from pages containing that literal text. We also map the query into semantic space and then search for matches in an index of images that have also been mapped into that same semantic space. Deep learning is used to discover the semantic representation of queries and images such that related items are co-located in semantic space. This approach allows Bing to provide high quality results even from pages where no such query terms are present. We do this at internet scale, searching billions of images in tens of milliseconds for every image search query issued on Bing.
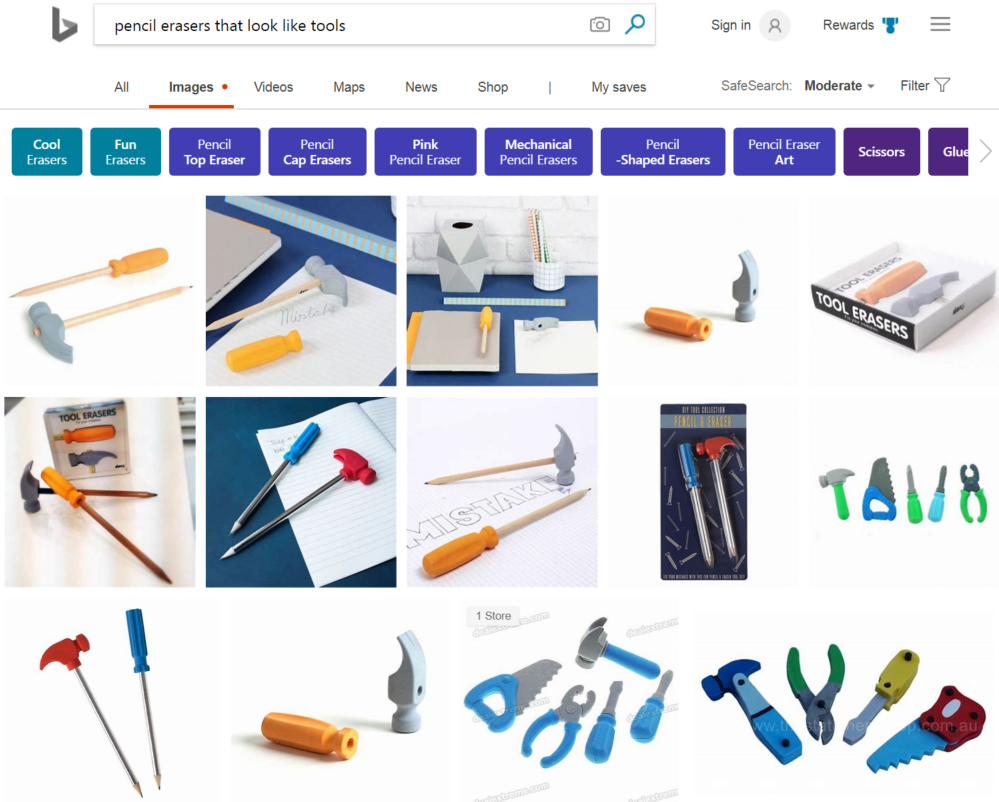
Looking inside an image
In image search a picture is really ‘worth a thousand words’ because describing a picture with natural language can be done in 'thousands’ of ways. For example, the image below could be described as ‘man swimming along with a sperm whale,’ or ‘wildlife in the ocean.’ In Bing image search, we need to understand that both of these queries can be well answered by this image. Capturing the semantic association between text and images is not straightforward, and this is where deep learning comes into play.
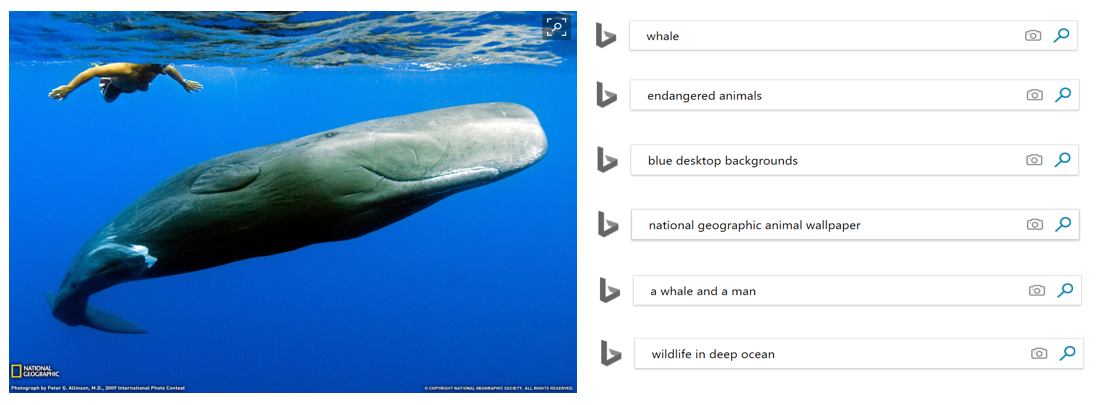
Deep learning computer vision techniques let us look inside an image, understand its semantic meaning and represent it as a vector through a process called image embedding. This vector needs to simultaneously represent that the image above is about a whale, contains a man, has waves at the top, has a strong blue background, etc. That’s a lot of information to squeeze into one vector! Similarly, deep learning natural language processing techniques let us read the words of a query and represent it as a vector through a process called text embedding. A model is first trained using deep learning techniques to map (embed) a query and an image to a high dimensional vector space in such a way that the corresponding vectors are similar if the image is semantically relevant to the query, and further apart otherwise.
So we have some vectors of queries and images, but how does that let us search billions of images in tens of milliseconds to satisfy a Bing Image Search query?
Deep image ranking
The goal of Bing Image Search is to retrieve the most relevant images for a given text query. A very very simplified description of this large-scale search operation consists of three major stages:
-
A matching stage – to select candidate images from a huge index of images
-
Multiple ranking stages – to use computationally expensive methods to score each candidate image independently and rank all images
-
Multiple set ranking stages – to re-rank previous candidates lists considering information from the entire candidate set, not just independent images
In Deep Image Ranking we leverage image and text embedding vectors at each stage to allow us to better capture semantic intent of queries and images. The graph below illustrates the overall infrastructure of our deep image ranking work, and we will introduce each component in detail.

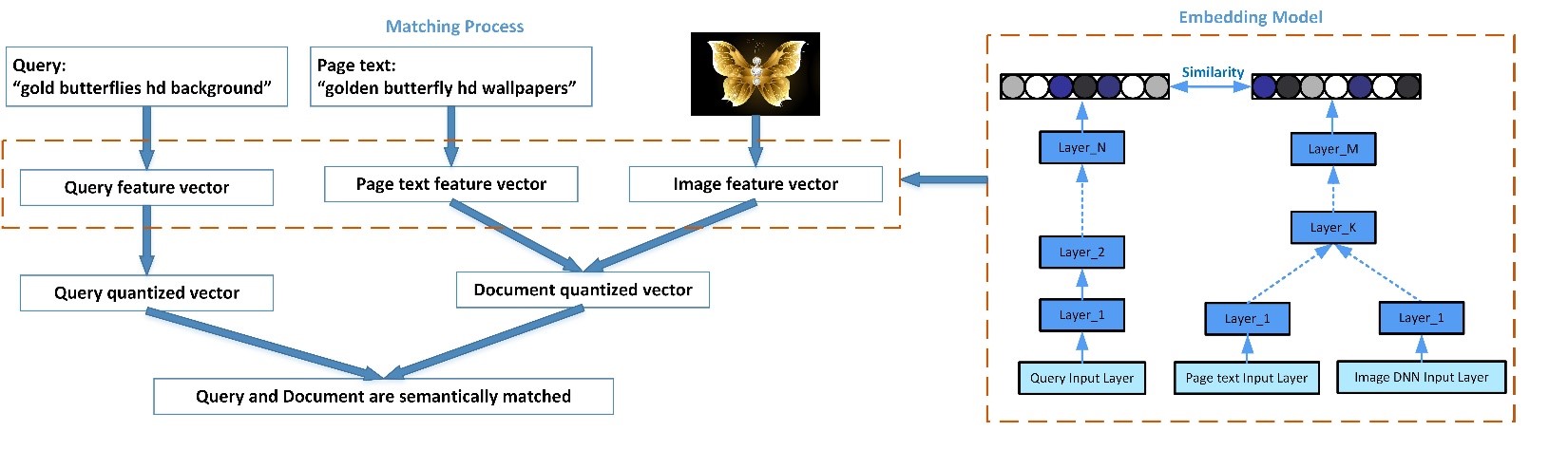
Deep learning in matching
The matching stage selects a candidate set of images from billions of images to be subsequently processed by the ranking stages. During matching, it is essential to obtain a result set with high recall and moderate precision. To achieve this, query, image and page text are embedded by a deep learning model into embedding vectors. We then use an efficient vector search algorithm to scan a billions-scale index to find the N-best document vectors for a query vector. We have experimented with two approaches: (i) an optimized version of the classical Approximate Nearest Neighbor (ANN) search, and (ii) a quantized matching approach where dense vectors are first quantized into sparse vectors which allows us to execute vector search considerably faster but with a trade-off in precision. After evaluating several approaches balancing different levels of precision and performance, and various combinations of query, image and page text embedding vectors, we picked the one providing optimal combination of speed and quality. Let us look at an example in the diagram below: the left part shows that even though the page text ‘golden butterfly hd wallpapers’ is not exactly the same as the query ‘gold butterflies hd background’, we are able to retrieve the relevant image based on query embedding, page text embedding and image embedding, which are generated from the deep learning model as shown in the right diagram.
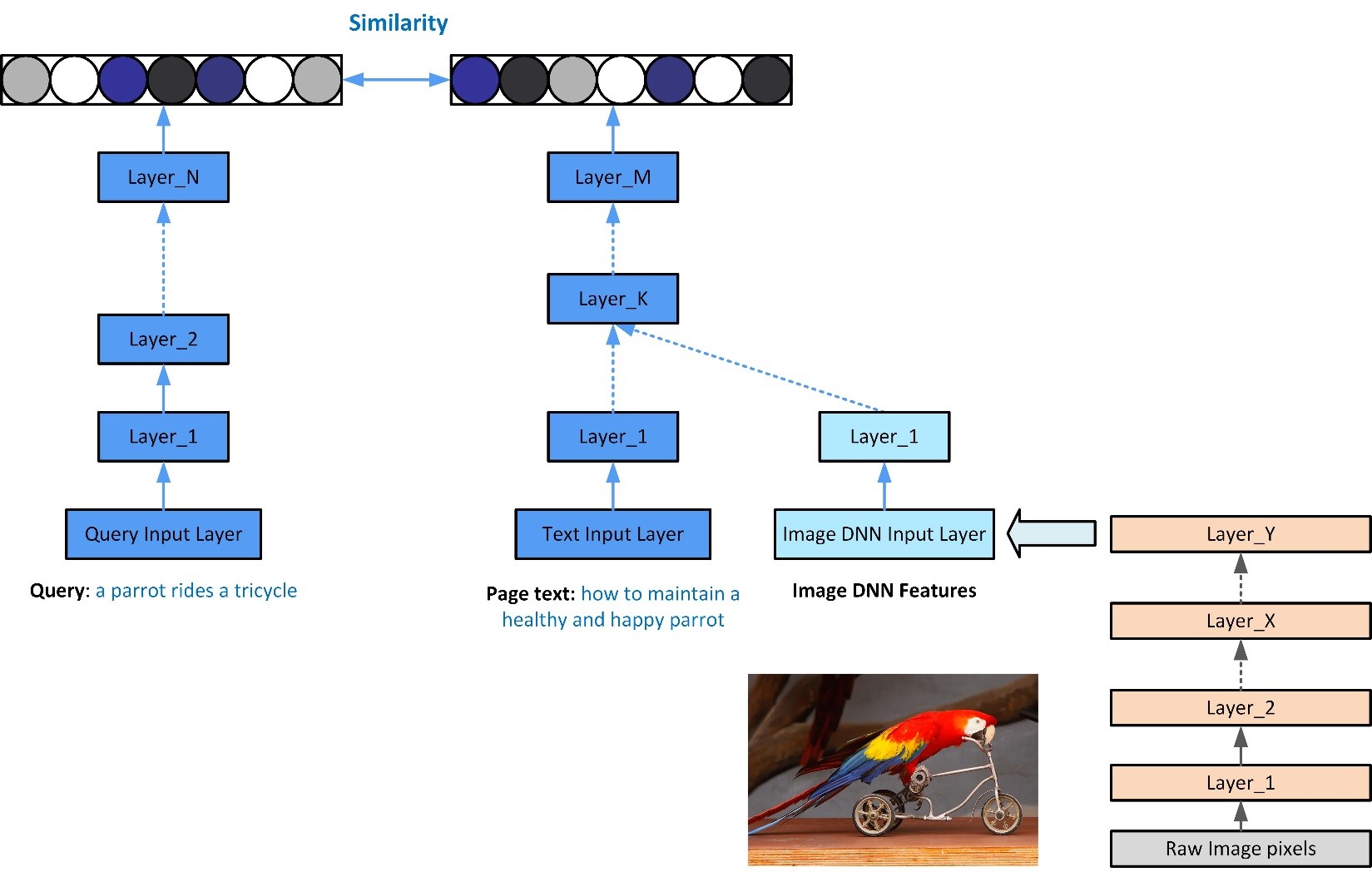
Deep learning in ranking
The next step is to rank all the candidate images according to their relevance to the query. The set of images we consider here is much smaller than in the previous step and therefore we can be more liberal with computations. Here we reuse the previously computed embedding vectors but do more exact calculations of semantic distance between the vectors. Using semantic matching of vectors is particularly invaluable at this stage when the text on the page hosting the image is not representative of the image, as we are able to directly ‘look at the image’ and consider its relevance to the query. For example, in the diagram below, the page contains the text ‘how to maintain a healthy and happy parrot’ however we are still able to recognize that the image matches the query ‘a parrot rides a tricycle’ because we are looking inside the image using image embedding.
Deep learning in set ranking
The set ranking stages aim to further optimize the ranking order of a list of images for a given query by considering information from all images in the candidate list. For example, for the query ‘cat in a box,’ if 95 out of 100 images are relevant, while the remaining 5 images are of a ‘dog in a box,’ we want to consider the consistent information of the 95 good images and demote the 5 bad images.
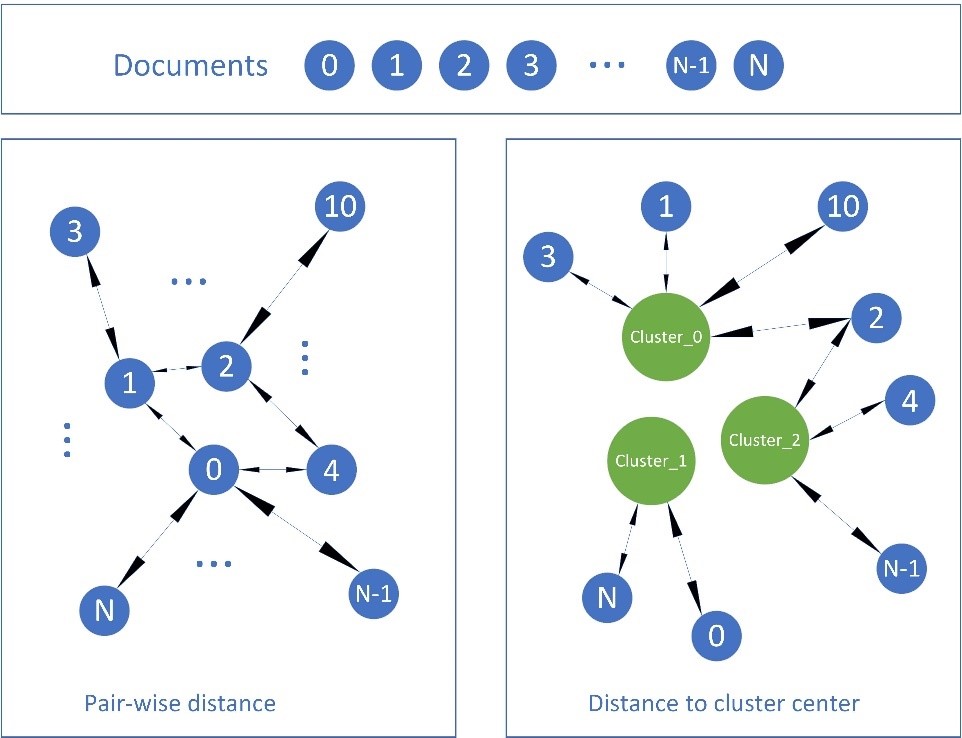
Once again, we can use deep learning here to embed the image and page text into vectors and then compute pair-wise distances between all images in the candidate list. We further compute higher-order features from these pairwise distances and use them to re-rank the candidate list. For example, the diagram below shows one such approach where we consider the distance of each image from the cluster centroids estimated from the vectors of the top-N images. With these distances available we can now easily identify the few ‘dog in a box’ images as inconsistent with the majority of the good results and eliminate them.
So, what is the end result?
Putting this all together, we now have an image ranking system that considers search in semantic space and allows more complex queries to be intelligently understood. Here are examples of some of the large improvements we have seen in image search quality:
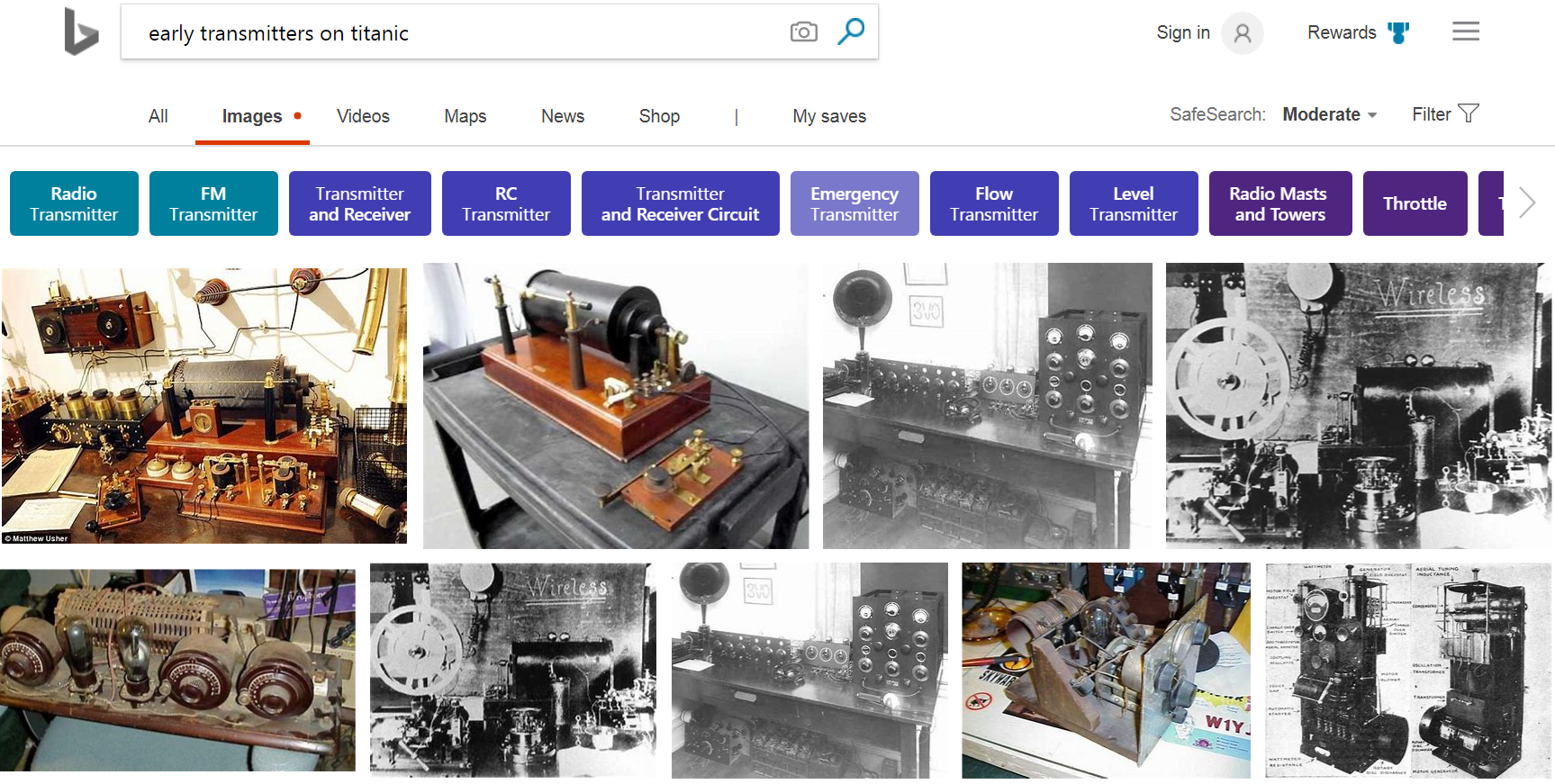
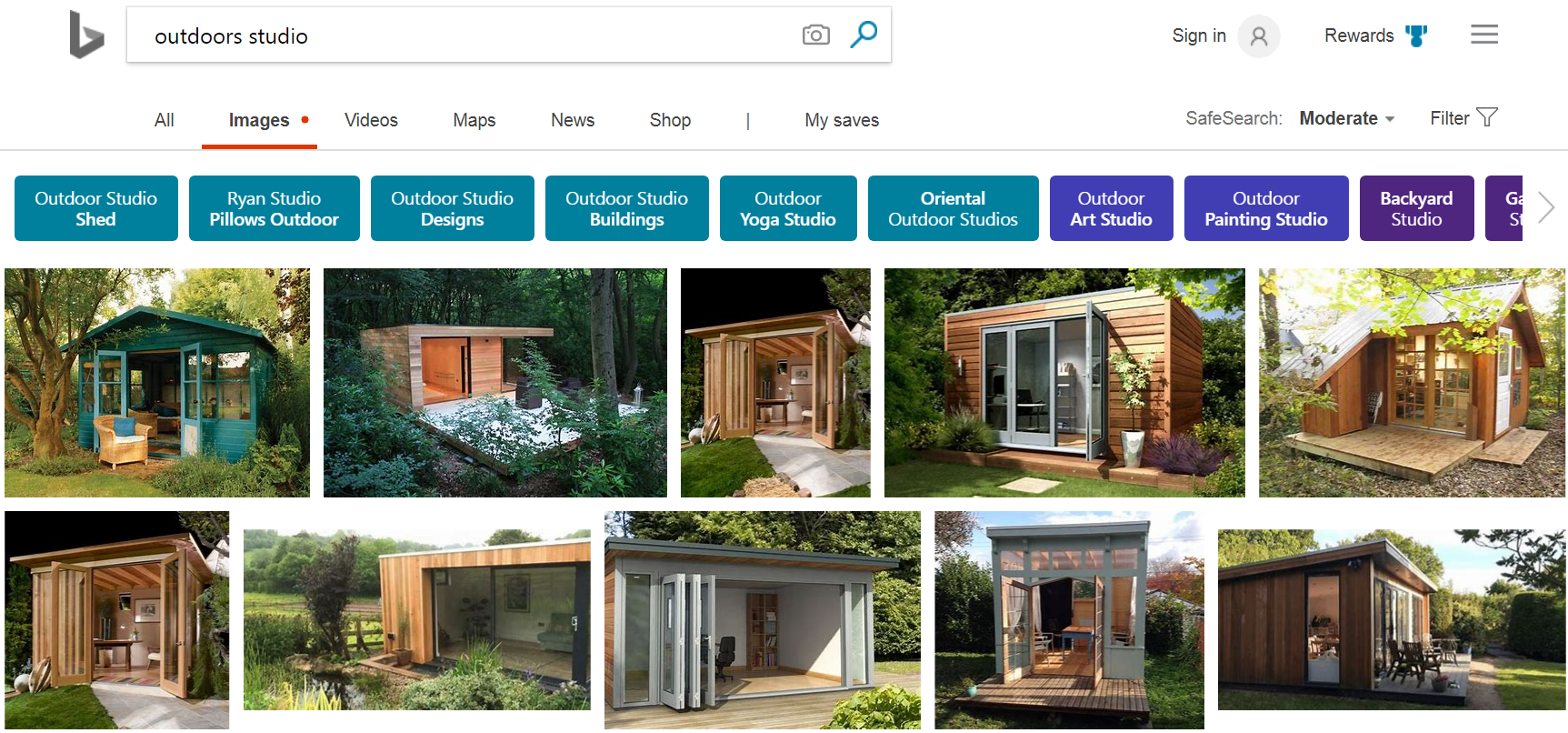
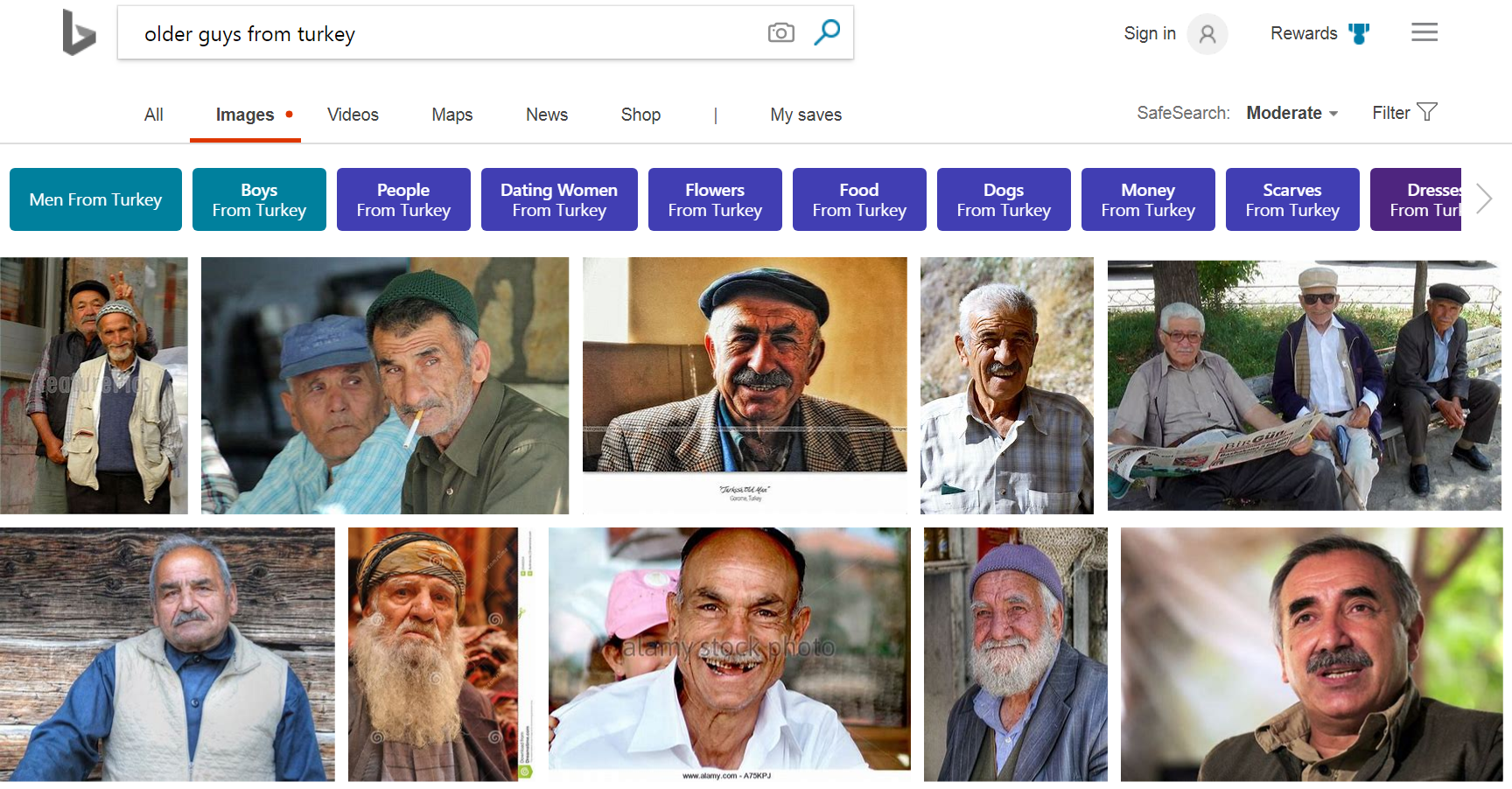
Deep image ranking has improved Bing results across the board, but where it stands out is when there is insufficient text on the page, and where semantic understanding of the query is key to providing optimal image search results. However, there is no silver bullet, and there are still many complex queries that we are trying to improve. We continue to look for more ways to train our deep image ranking to provide great results to the hardest queries using the most elegant and scalable solutions.
If you have any feedback, let us know using Bing Listens or simply click on ‘Feedback’ on Bing Image Search!
– Bing Image Search Relevance Team
Source: Bing Blog Feed