How We Built (Rebuilt!) Intune into a Leading Globally Scaled Cloud Service
This is something we usually dont do here at Microsoft, but today I want to share a blog post (included below) that was written for internal purposes only.
Let me answer your first question: But why are you releasing this information?
Simply put, as I meet with customers navigating their own unique digital transformation, I often hear that IT teams (and their leaders) are struggling with how to scale their infrastructure or apps not just in the cloud but also in terms of what the cloud will demand from them during this process.
I deeply understand that feeling; I have been in those shoes.
My goal with the information below is to share how we built our own global cloud service and I hope some of this information can act as a blueprint in your efforts to build something of your own.
We architected Intune from the cloud and for the cloud and we ended up with the worlds leading mobility service and the only one with true cloud scale.
This architecture is the best way to enable our customers to achieve their goals, safeguard their data, and protect their intellectual property all without hitting any limits on productivity or scale.
It is a rare experience to get to work on something where you started from scratch (literally: File-New), and then get to operate and optimize what you have created to a high-scale cloud service that is servicing billions of transactions every day.
Working on Intune has been one of these rare and rewarding opportunities.
What stands out to me about this blog post is the genius of the engineers who did this work. Theres no other way to say it. As you look around at the massive (and always growing) mobile management marketplace today, Intune is unique in that it is a true cloud service. Other solutions claim that they have a cloud model, but, at their core, they are simply not built as a cloud service.
The Intune engineering team has become one of the teams at Microsoft that is now regularly sought-out and asked to present the how-tos of our journey to a high-scale cloud service. When we first started Intune, Azure was just a glimmer in the eyes of a few incredible engineers; because of this, the initial architecture was not built on Azure. As we saw the usage of Intune begin to really scale in 2015, we knew we had to rearchitect it to be a modern Azure service that was built on a cloud-based micro-service architecture.
This ended up being a monumental decision.
The reason this decision mattered so much is obvious in retrospect: As a service scales to 10s of millions, and then 100s of millions, and then billions of devices and apps a cloud-based architecture is the only thing that can deliver the reliability, scale, and quality you expect. Also, without a cloud-based architecture, our engineering teams couldnt respond fast enough to customer needs.
Since making this change, I cannot count the number of customers that have commented on the changes in reliability and performance they have seen, as well as the speed at which we are delivering new innovations.
This is all possible because of architecture. Architecture really, really matters.
This perspective on this architecture came about after many hundreds of hours spent examining other solutions before we decided to rebuild Intune. Before we began that work on Intune, we intensively analyzed and evaluated a number of competing solutions to see if we should buy one of them instead. None of the solutions we considered were cloud services none. Every single one was a traditional on-prem Client-Server product being hosted in a datacenter and called a cloud service.
That was not a path toward hyperscale.
One way you can easily tell if a product is a client-server model or a cloud service is if there is a version number. If you see something like Product X v8.3 then you immediately know its not a cloud service. There is no such thing as a version number in a cloud service when the service is being updated multiple times a day.
I am excited about the future of Intune because there are scenarios that only Cloud services can perform this means that the Intune engineering team are already delivering solutions for problems our competitors havent even discovered yet, and it means the expertise of this team will just keep accelerating to anticipate and meet our customers needs.
As an engineering leader, it is incredibly exciting to consider what this means for the services and tools well build for our customers, as well as the ways well be able to respond when those customers come to us with new projects and new challenges.
If you havent switched to Intune yet, take a few minutes to read this post and then lets get in touch.
Intunes Journey to a Highly Scalable Globally Distributed Cloud Service
Starting around the 2nd half of 2015, Intune, which is part of Enterprise Mobility + Security (EMS), had begun its journey as the fastest growing business in the history of Microsoft. We started seeing signs of this rapid business growth result in a corresponding rapid increase in back end operations at scale. At the same time, we were also innovating across various areas of our service within Intune, in Azure, and other dependent areas. Balancing the innovation and rapid growth in a very short time was an interesting and difficult challenge we faced in Intune. We had some mitigations in place, but we wanted to be ahead of the curve in terms of scale and performance, and this pace in growth was somewhat of a wake up call to accelerate our journey to become a more mature and scalable globally distributed cloud services. Over the next few months, we embarked on making significant changes in the way we architected, operated, and ran our services.
This blog is a 4-part series that will describe Intunes cloud services journey to become one of the most mature and scalable cloud service running on Azure. Today, we are one of the most mature services operating at high scale while constantly improving the 6 pillars of availability, reliability, performance, scale, security, and agility. The 4-part blog series is roughly divided into the following topics:nd half of 2015, Intune, which is part of Enterprise Mobility + Security (EMS), had begun its journey as the fastest growing business in the history of Microsoft. We started seeing signs of this rapid business growth result in a corresponding rapid increase in back end operations at scale. At the same time, we were also innovating across various areas of our service within Intune, in Azure, and other dependent areas.
Balancing the innovation and rapid growth in a very short time was an interesting and difficult challenge we faced in Intune. We had some mitigations in place, but we wanted to be ahead of the curve in terms of scale and performance, and this pace in growth was somewhat of a wake up call to accelerate our journey to become a more mature and scalable globally distributed cloud services. Over the next few months, we embarked on making significant changes in the way we architected, operated, and ran our services.
Architecture and background, and our rapid reactive actions to improve customer satisfaction and make a positive impact towards business growth.
- Our proactive measures and actions to prepare for immediate future growth.
- Actions to mature the service to be highly available and scalable and be on-par with other high scale world class services.
- Path towards a pioneering service setting an example for various high scale operations in distributed systems.
Each of the blogs will summarize the learnings, in addition to explaining the topic in short detail. The first of the 4-series is described below. The remaining 3 topics will be covered in future blogs in the coming months.
Background and Architecture
In 2015, Intunes composition was a combination of a set of services running on physical machines hosted in a private data center and a set of distributed services running on Azure. By 2018, all Intune services have moved to running on Azure. This and future blogs are focused only on the distributed services running on Azure. The migration of services running on physical machines to Azure is a different journey and perhaps a blog at some point in the future. The rest of this section focuses on the background and architecture as of 2015.
Global Architectural View
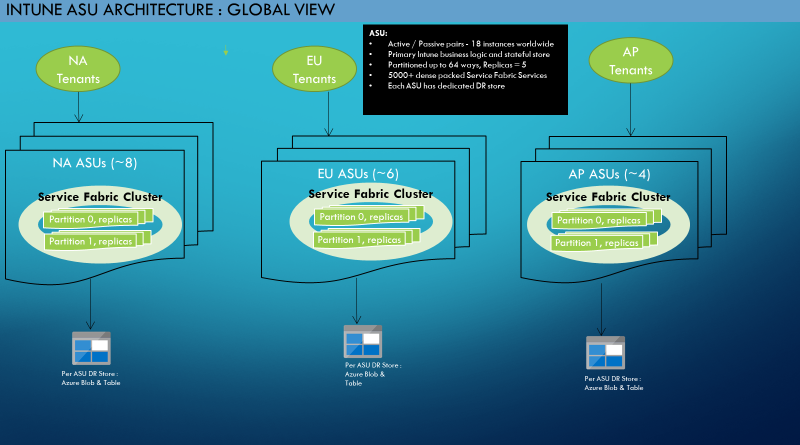
Intune s cloud services are built on top of Azure Service Fabric (ASF). All services are deployed to an ASF cluster consisting of a group of front-end (FE) and middle-tier (MT) nodes. The FE nodes are hosted on A4 sku (14 GB, 8 cores). The MT nodes are hosted on A7 sku (56 GB, 8 cores). A cluster is completely isolated and independent of other clusters they cannot access each other in any way or form as they are hosted in completely different subscriptions and data centers. There are 18 such ASF clusters throughout the world, spread across 3 regions North America (NA), Europe (EU), and Asia Pacific (AP). Each ASF cluster has an identical set of services deployed and perform identical functionality. These services consist of stateless and partitioned stateful services. Figure 1 shows the global architectural view.

Figure 1: Intunes Global Clusters (a.k.a. Azure Scale Unit, ASU) – Architecture View (2015)sku (14 GB, 8 cores). The MT nodes are hosted on A7 sku (56 GB, 8 cores). A cluster is completely isolated and independent of other clusters they cannot access each other in any way or form as they are hosted in completely different subscriptions and data centers. There are 18 such ASF clusters throughout the world, spread across 3 regions North America (NA), Europe (EU), and Asia Pacific (AP). Each ASF cluster has an identical set of services deployed and perform identical functionality. These services consist of stateless and partitioned stateful services. Figure 1 shows the global architectural view.
Cluster Architecture Drilldown
Within each cluster, we have 5000+ services running with a set of ~80 unique types of stateless microservices and ~40 unique types of stateful microservices. Stateless services run multiple instances on all FE nodes routed by Azure load balancer. Stateful services and some high value stateless services run on MT nodes. Stateful services are built on in-memory architecture that we built in-house as a No-SQL database (recall we are talking about 2015 here).
The stateful in-memory store we implemented is a combination of AVL trees and hash sets to allow extremely fast writes, gets, table scans, and secondary index searches. These stateful services are partitioned for scale out. Each partition has 5 replicas to handle availability. One of these 5 acts as the primary replica where all requests are handled. The remaining 4 are secondary replicas replicated from the primary. Some of our services require strong consistency for their data operations, which means we need a quorum of replicas in order to satisfy writes. In these scenarios, we prefer CP over AP in the CAP theorem, i.e., when a quorum of replicas is not available, we fail writes and hence loss of availability. Some of our scenarios are fine with eventual consistency, and we would benefit from AP over CP, but for simplicity sake, our initial architecture supported strong consistency across all services. So, at this point, we are CP.
ASF does a great job in many aspects, one of which is densely packing services across the cluster. The typical number of our processes running on each MT node ranges from 30-50 hosting multiple stateful replicas. It also does very well on handling all the complexities of managing and orchestrating replica failover and movement, performing rolling upgrades for all our service deployments, and load balancing across the cluster. If/when the primary replica dies, a secondary replica is automatically promoted to primary by ASF, and a new secondary replica is built to satisfy the 5 replica requirement. The new secondary replica initiates and completes a full memory to memory data transfer from the primary to the secondary. We also periodically backup data in an external persisted Azure table/blob storage with a 10-minute RPO to recover from cases where all replicas are lost in a disaster or partition loss. Figure 2 shows the cluster view. Figure 2 shows the cluster view.

Scale Figure 2: Intunes Azure Scale Unit (a.k.a. cluster or ASU) Architecture (2015)RPO to recover from cases where all replicas are lost in a disaster or partition loss. Figure 2 shows the cluster view.. Figure 2 shows the cluster view.
Issues
As mentioned earlier, with the rapid usage growth (approximately going from 3bn transactions to 7 bn per day), towards the end of 2015 and beginning of 2016, our back end services started seeing a corresponding huge increase in traffic. So, we started looking into devising tactical solutions to give immediate relief to handle any issues arising out of these growing pains.
Issue #1:
The very first thing we realized was that we needed proper telemetry and alerting. The scale at which we needed telemetry was also undergoing much rapid innovation from the underlying Azure infrastructure at this point, and we could not leverage it immediately due to the GA timings, etc. So, from a tactical point of view, we had to invent a few instrumentation/diagnostic solutions in a very quick manner, so we can get sufficient data to start mitigations. With the correct telemetry in place, we started gathering the data on what were the top most critical issues we should address to realize the biggest relief.
The quick investments in telemetry paid off in a big way. We were able to investigate and determine tactical solutions and iterate in a fast manner. The rest of the issues were all driven by this short term, but high impact investments in telemetry.
Issue #2:
Telemetry made us aware that some partitions were handling huge amounts of data. A single partition sometimes would store millions of objects and the transaction rates reached up to 6 billion per day across the clusters. Increased data meant increase in data transfer when secondary replicas needed to be built as and when any of the existing primary/secondary replicas died or had to be load balanced. The more the data, the more time it would take to build the secondary with associated memory and CPU costs.
Much of this time was due to serialization/deserialization of the data required to transfer between the replicas during rebuild. We were using data contract serializer, and after various perf investigations with many serializers, we settled on the change to using Avro. Avro gave us a 50% throughput and CPU improvement, and significantly reduced the time it took to rebuild. For example, for a 4 GB data transfer, our rebuilds which were taking up to 35 mins would complete in <= 20 minutes. This was not optimal, but we were looking at immediate relief and this solution helped us in that respect. I will share in my next blog how we reduced this time to complete in seconds from 20 minutes.
Issue #3:
The usage growth also brought in new traffic and search patterns for our algorithms that were not fully optimized to handle efficiently (CPU/memory wise). We designed efficient secondary index searching with AVL trees, however, for certain search patterns, we could be even more optimized. Our assumption was that the secondary index trees typically would have much smaller sizes compared to the main tree that do full table scans, and should meet all our needs. However, when we were looking at some of the high CPU issues, we noticed a traffic pattern that occasionally pegged the CPU for certain secondary index searching. Further analysis showed us that paging and order by searches with millions of objects in a secondary index can cause extremely high CPU and impact all services running on that node.
This was a great insight that we could immediately react to and design an alternative algorithm. For the paging and order by searches, we designed and implemented a max heap approach to replace the AVL tree. The time complexity for inserts and searches is an order of magnitude better for the max heap. Inserting 1M objects reduced our time from 5 seconds to 250 milliseconds, and we saw order by (basically sorting) improvements for 1M objects to go from 5 seconds to 1.5 seconds. Given the # of search queries that were performing these types of operations, this improvement resulted in a significant saving for our memory and CPU consumption in the cluster.saving for our memory and CPU consumption in the cluster.
Issue #4: Max heap approach to replace the AVL tree.
The time complexity for inserts and searches is an order of magnitude better for the max heap. Inserting 1M objects reduced our time from 5 seconds to 250 milliseconds, and we saw order by (basically sorting) improvements for 1M objects to go from 5 seconds to 1.5 seconds. Given the # of search queries that were performing these types of operations, this improvement resulted in a significant saving for our memory and CPU consumption in the cluster.saving for our memory and CPU consumption in the cluster.
A vast majority of all the growth impact was seen when we were performing deployments/upgrades. And these issues got further exacerbated when our FE and MT nodes got rebooted by Azure as part of its OS patching schedule. These nodes were rebooted upgrade domain (UD) by UD in a sequential manner, with a hard limit of 20 mins for each UD to be completely functional before moving on to the next UD upgrade.
There were 2 categories of issues that surfaced for us with the upgrades:
- The replica count for stateful services was equal to the number of UDs (both were 5). So, when one UD was being upgraded, ASF had to move all the replicas from that UD to one of the other 4, while maintaining a variety of constraints such as proper distribution of replicas to maintain fault domain placements, primary/secondary not being on the same nodes, and variety of others. So, it required a fair amount of replica movement and density during upgrades. From issue #2 above, we knew some rebuilds could take up to 20 mins, which meant that secondary replicas could not be fully ready before the next UD got upgraded. The net effect of this was we lost quorum because sufficient number of replicas were not active to satisfy writes during upgrades. Figure 3 shows the effect of the replica density changes during upgrades. The steep increase from ~350 replicas to ~1000 replicas for one of our services is an example of the amount of rebuilding that was happening. Our immediate reaction was to bump up the SKU for the nodes to get some relief, but the underlying platform didnt support an in-place upgrade of the sku. Thus, we were required to failover to a new cluster, which meant we needed to do data migration. This would be a very complex procedure, so we dropped this idea. I will describe in one of the next blog posts how we overcame this limitation.
- Intune and ASF teams performed deep analysis of this problem, and with the help of ASF team, we finally determined that the optimal configuration was using 4 replicas with 5 UDs, so that one UD is always available to take on additional replicas and avoid excessive movement of replicas. This provided a significant boost to our cluster stability, and the 3x delta replica density during upgrades dropped by 50-75%.
 Figure 3: Replica Count and Density Impact During Upgrades
Figure 3: Replica Count and Density Impact During Upgrades
Finally, we also noticed that our cluster could be better balanced in terms of replica counts and memory consumption. Some nodes were highly utilized, while some nodes were almost idle. Obviously, this put undue pressure on the heavily loaded nodes when there was traffic spike or upgrades. Our solution was to implement load balancing metrics, reporting, and configuration in our clusters. The impact of this is best shown in Figures 4 and 5 blue lines indicate the balance after our improvements. The X-axis is the node name we use.
 Figure 4: Per Node Replica Counts Before and After Load Balancing Improvements.
Figure 4: Per Node Replica Counts Before and After Load Balancing Improvements.
 Figure 5: Per Node Memory Consumption Before and After Load Balancing Improvements.
Figure 5: Per Node Memory Consumption Before and After Load Balancing Improvements.
Learnings
- There are 4 top level learnings that this experience taught us that I believe are applicable to any large-scale cloud service:
- Make telemetry and alerting one of the most critical parts of your design. Monitor the telemetry and alerting, iterate, and refine in pre-production environment before exposing the feature to your customers in production.
- Know your dependencies. If your scale solution doesnt align to your dependent platform, all bets are off. For example, if your solution to scale out is to increase from 10 nodes to 500 nodes, ensure that the dependent platform (Azure or AWS or whatever it is) supports that increase, and the length of time it takes to do so. For example, if there is a limit on increasing it by few nodes at a time, you will need to adjust your reactive mechanism (alerts, etc.) to account for this delay. Similarly, another example is scale up. If your scale up solution is to do a sku upgrade, ensure that your dependent platform will support an in-place upgrade of a low performance sku to a high performance sku.
- Continually validate your assumptions. Many cloud services and platforms are still evolving, and the assumptions you made just a few months back may not be valid any more in many respects including dependent platforms design/architecture, alternative available better/optimized solutions, deprecated features, etc. Part of this could be monitoring your core code paths for changes in traffic patterns and ensuring that the design/algorithms/implementation you put in place are still valid for their usage. Cloud service traffic usage patterns can and will change and a solution that was valid few months back may not be optimal anymore, and needs to be revisited/replaced with a more efficient one.
- Make it a priority to do capacity planning. Determine how you can do predictive capacity analysis and ensure you review it at a regular cadence. This will make a difference between being reactive and pro-active for customer impacting scale issues.
Conclusion
Implementation and rollout of all the above solutions to production took us about 3-4 months. By April 2016, the results were highly encouraging. There was a vast improvement in our cluster stability, availability, and reliability. This was also felt by our customers who gave very positive comments and reactions to the improvements we had made in reliability and stability. This was a huge encouraging step, but we had all the learnings from above to take us forward to make it even better with further improvements. Our journey to a mature and scalable distributed cloud service had begun.
Source: EM+S Blog Feed