Announcing automated ML capability in Azure Machine Learning
This post is co-authored by Sharon Gillett, Technical Advisor and Principal Program Manager, Research.
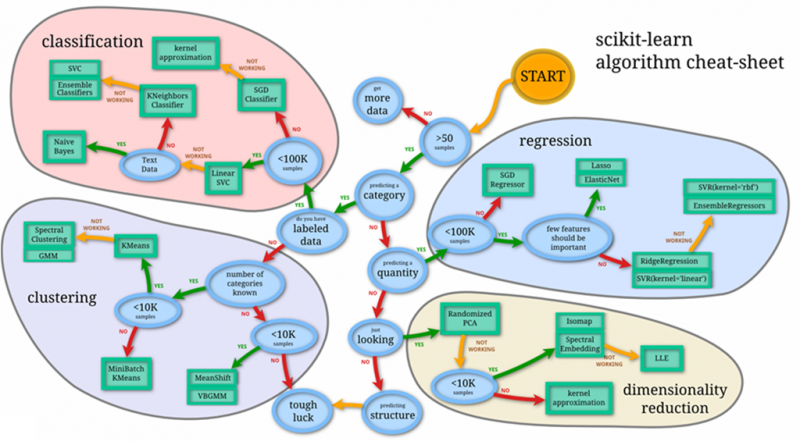
Intelligent experiences powered by machine learning can seem like magic to users. Developing them, however, can be anything but. Consider this “simple” tutorial chart from the scikit-learn machine learning library:

Source: scikit-learn machine learning library
Data scientists and developers face a series of sequential and interconnected decisions along the way to achieving "magic" machine learning solutions. For example, should they transform the input data, and if so, how – by removing nulls, rescaling, or something else entirely? What machine learning algorithm would be best – a support vector machine (SVM), logistic regression, or a tree-based classifier? What parameter values should they use for the chosen classifier – including decisions such as what the max depth and min split count should be for a tree-based classifier? And many more.
Ultimately, all these decisions will determine the accuracy of the machine learning pipeline – the combination of data pre-processing steps, learning algorithms, and hyperparameter settings that go into each machine learning solution.

Unfortunately, the problem of finding the best machine learning pipeline for a given dataset scales faster than the time available for data science projects. Aiming for higher accuracy in one project may delay or preclude pursuing other projects. Or data scientists may have to settle for less-than-optimal accuracy in some projects, so they can make time for others. And when machine learning solutions need to be maintained as data evolves – for example, models that detect spam or fraud, or models that depend on weather data – there’s always a tradeoff between keeping existing solutions up to date and devoting scarce data scientist time to new problems.
But what if a developer or data scientist could access an automated service that identifies the best machine learning pipelines for their labelled data? Automated machine learning (which we abbreviate as automated ML in the rest of this post) is a new capability that does exactly that. Automated ML is now in preview, accessible through the Azure Machine Learning service. Automated ML empowers customers, with or without data science expertise, to identify an end-to-end machine learning pipeline for any problem, achieving higher accuracy while spending far less of their time. And it enables a significantly larger number of experiments to be run, resulting in faster iteration towards production-ready intelligent experiences.

Microsoft is committed to democratizing AI through our products. By making automated ML available through the Azure Machine Learning service, we're empowering data scientists with a powerful productivity tool. We're working on making automated ML accessible through PowerBI, so that business analysts and BI professionals can also take advantage of machine learning. And stay tuned as we continue to incorporate it into other product channels to bring the power of automated ML to everyone.
Now, that's magic! But how does automated ML really work?
Automated ML is based on a breakthrough from our Microsoft Research division. The approach combines ideas from collaborative filtering and Bayesian optimization to search an enormous space of possible machine learning pipelines intelligently and efficiently. It's essentially a recommender system for machine learning pipelines. Similar to how streaming services recommend movies for users, automated ML recommends machine learning pipelines for data sets.
Streaming service (numbers represent user ratings for movies)

Automated ML (numbers represent accuracy of pipelines evaluated on datasets)

As indicated by the distributions shown on the right side of the figures above, automated ML also takes uncertainty into account, incorporating a probabilistic model to determine the best pipeline to try next. This approach allows automated ML to explore the most promising possibilities without exhaustive search, and to converge on the best pipelines for the user’s data faster than competing “brute force” approaches.
Just as important, automated ML accomplishes all this without having to see the customer’s data, preserving privacy. Automated ML is designed to not look at the customer’s data. Customer data and execution of the machine learning pipeline both live in the customer’s cloud subscription (or their local machine), which they have complete control of. Only the results of each pipeline run are sent back to the automated ML service, which then makes an intelligent, probabilistic choice of which pipelines should be tried next.
No need to “see” the data

We trained automated ML’s probabilistic model by running hundreds of millions of experiments, each involving evaluation of a pipeline on a data set. This training now allows the automated ML service to find good solutions quickly for your new problems. And the model continues to learn and improve as it runs on new ML problems – even though, as mentioned above, it does not see your data.
Automated ML is available to try in the preview of Azure Machine Learning. We currently support classification and regression ML model recommendation on numeric and text data, with support for automatic feature generation (including missing values imputations, encoding, normalizations and heuristics-based features), feature transformations and selection. Data scientists can use automated ML through the Azure Machine Learning Python SDK and Jupyter notebook experience. Training can be performed on a local machine or by leveraging the scale and performance of Azure by running it on Azure Machine Learning managed compute. Customers have the flexibility to pick a pipeline from automated ML and customize it before deployment. Model explainability, ensemble models, full support for Azure Databricks and improvements to automated feature engineering will be coming soon.
Get started by visiting our documentation and let us know what you think – we look forward to making automated ML better for you!
Source: Azure Blog Feed