Microsoft’s new neural text-to-speech service helps machines speak like people
Microsoft has reached a milestone in text-to-speech synthesis with a production system that uses deep neural networks to make the voices of computers nearly indistinguishable from recordings of people. With the human-like natural prosody and clear articulation of words, Neural TTS has significantly reduced listening fatigue when you interact with AI systems.
Our team demonstrated our neural-network powered text-to-speech capability at the Microsoft Ignite conference in Orlando, Florida, this week. The capability is currently available in preview through Azure Cognitive Services Speech Services.
Neural text-to-speech can be used to make interactions with chatbots and virtual assistants more natural and engaging, convert digital texts such as e-books into audiobooks and enhance in-car navigation systems.
The milestone in text-to-speech joins a string of breakthroughs that our group has achieved over the past two years, including human parity in conversational speech recognition and human parity in machine translation.

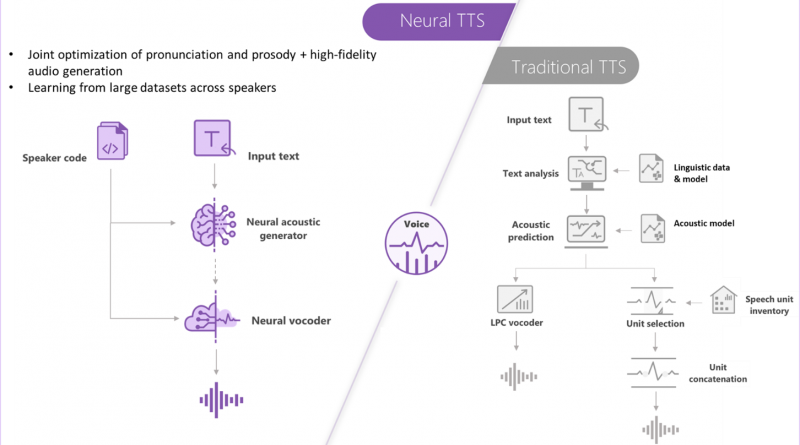
Our text-to-speech capability uses deep neural networks to overcome the limits of traditional text-to-speech systems in matching the patterns of stress and intonation in spoken language, called prosody, and in synthesizing the units of speech into a computer voice.
Traditional text-to-speech systems break down prosody into separate linguistic analysis and acoustic prediction steps that are governed by independent models. That can result in muffled, buzzy voice synthesis. Our neural capability does prosody prediction and voice synthesis simultaneously. The result is a more fluid and natural-sounding voice.
| Sentence | Recording | Neural TTS |
| The third type, a logarithm of the unsigned fold change, is undoubtedly the most tractable. |  |
 |
| As the name suggests, the original submarines came from Yugoslavia. |  |
 |
| This is easy enough if you have an unfinished attic directly above the bathroom. |  |
 |
By using the computational power of Azure, we can deliver real-time streaming, which is useful for situations such as interacting with a chatbot or virtual assistant. The capability is served in the Azure Kubernetes Service. This ensures high scalability and availability and gives customers the ability to use neural text-to-speech and traditional text-to-speech from a single endpoint.
The preview service is currently offering two pre-built neural text-to-speech voices in English – Jessa and Guy. More languages will be available soon, as well as customization services in 49 languages for customers who want to build branded voices optimized for their specific needs.
To learn more, visit us.
Source: Azure Blog Feed