Near real-time analytics in Azure SQL Data Warehouse
As the pace of data creation increases through IoT scenarios and streams of data, there is a growing demand for faster access to data for analysis. This demand for near-real-time analytics is seen across all industry segments from retail giants making real-time price changes, to manufacturing plants using anomaly detection to determine potential problems on the assembly line before they happen, to mine and gas companies using hi-tech drill sensor readings to know precisely what is happening hundreds of feet below the earth's surface as it's happening. We have seen across all customers that the benefits of near real-time analytics can be enormous.
Today, we are excited to announce near real-time analytical capabilities in Azure SQL Data Warehouse. This architecture is made possible through the public preview of Streaming Ingestion into SQL DW from Azure Databricks Streaming Dataframes.
Structured Streaming in Azure Databricks
Azure Databricks is a fully managed cloud service from Microsoft running Databricks Runtime. The service provides an enterprise-grade Apache Spark implementation on Azure. Structured Streaming in Apache Spark enables users to define a query over a stream of data in a scalable and fault tolerant way.
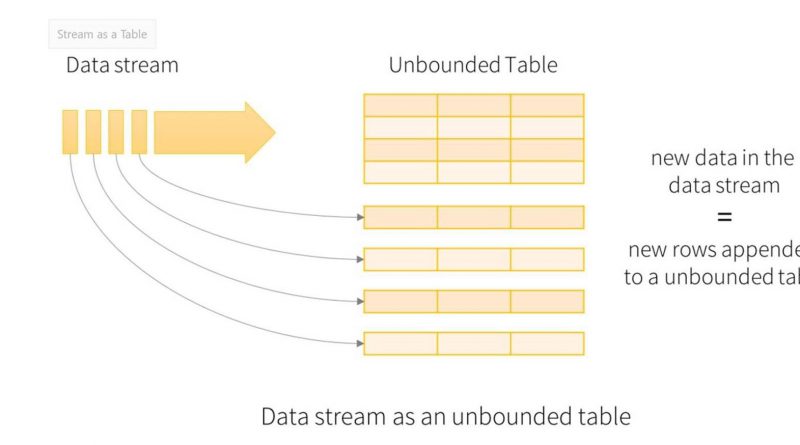
Structured Streaming is a scalable, fault-tolerant way to run queries over data streams. The streaming dataframe is an unbound table and the new data from the stream is appended to the table. Queries can be run to the appended sections and across the table as a whole.

Azure SQL Data Warehouse as output sink
While streaming queries are great for answering obvious questions over a stream of data like what is the avg, min, max values over time, it does not enable downstream analysts to have access to near real-time data. To achieve that, you will want to get the data into a SQL Data Warehouse as quickly as possible, so analysts can query, visualize, and interpret the near real-time data with tools like PowerBI.
Example: Rate Stream into SQL DW example
This a simple example to explain how the functionality works. Structured Stream has a data generator which produces a timestamp and a value at a given rate per second. We will use this mechanism to create a simple streaming example.
The first thing that you need to do is create a sink table in your SQL Data Warehouse. As we mentioned above, the rate stream will generate a timestamp and value, so we can use that as the schema of our table. To do this open your favorite database management tool and create the following table:
```sql CREATE TABLE [dbo].[Stream_CI] ( [timestamp] DATETIME NULL, [Value] BIGINT NULL ) WITH ( DISTRIBUTION = ROUND_ROBIN, CLUSTERED INDEX ([timestamp]) ) ``` A table with a ROUND_ROBIN distribution and a CLUSTERED INDEX on Timestamp provides the best compromise between ingestion speed and query performance for streaming data in a SQL Data Warehouse.
Now that we have our sink table in SQL DW let's look at the Azure Databricks portion. We have written all of the below code in Python, but the same functionality is available in R, Python, and Scala.
The first thing you want to do is set up your connection to your SQL DW where you just created the table and an Azure Storage Account.
```python # SQL DW related settings (used to setup the connection to the SQL DW instance) dwDatabase = <databaseName> dwServer = <servername> dwUser = <sqlUser> dwPass = <sqlUserPassword> dwJdbcPort = "1433" dwJdbcExtraOptions = "encrypt=true;trustServerCertificate=true;loginTimeout=30;" sqlDwUrl = "jdbc:sqlserver://" + dwServer + ".database.windows.net:" + dwJdbcPort + ";database=" + dwDatabase + ";user=" + dwUser+";password=" + dwPass + ";"+dwJdbcExtraOptions # Blob Storage related settings (used for temporary storage) # The value is the storage account url in the format of <accountName>.blob.core.windows.net blobStorage = <blobStorageAccount> blobContainer = <storageContainer> blobAccessKey = <accessKey> # Set up the Blob storage account access key in the notebook session conf. spark.conf.set( "fs.azure.account.key."+blobStorage , blobAccessKey) ```
In this block of code, we are using usernames and passwords for simplicity and speed of delivery, but this is not a best practice. We advise using secret scopes to securely store secrets in Azure Key Vault.
Now that we can connect to both our SQL DW and our Storage Account from Azure Databricks let's create a read stream and write the output to our SQL DW.
The most important parameters for the rate stream are the rowsPerSecond and the numPartitions. The rowsPerSecond specifies how many events per second the system will try to create. The numPartitions specifies how many partitions are allocated to creating the rows. If the rowsPerSecond is high and the system is not generating enough data, try using more partitions.
```python
# Prepare streaming source
df = spark.readStream
.format("rate")
.option("rowsPerSecond", "10000")
.option("numPartitions", "5")
.load()
```
To write the readStream to SQL DW, we need to use the "com.databricks.spark.sqldw" format. This format option is built into the DataBricks runtime and is available in all clusters running Databricks 4.3 or higher.
```python
# Structured Streaming API to continuously write the data to a table in SQL DW.
df.writeStream
.format("com.databricks.spark.sqldw")
.option("url", sqlDwUrl)
.option("tempDir", "wasbs://"+blobContainer+ "@" + blobStorage + "/tmpdir/stream")
.option("forwardSparkAzureStorageCredentials", "true")
.option("dbTable", "Stream_CI")
.option("checkpointLocation", "/checkpoint")
.trigger(processingTime="30 seconds")
.start()
```
This statement processes the rateStream every 30 seconds. The data is taken from the stream and written into the temporary storage location defined by the tempDir parameter. Once the files have landed in this location, SQL DW loads the data into the specified table using PolyBase. After the load is complete, the data on your storage location is deleted ensuring the data is read only once.
Now that the stream is generating data and writing it to SQL DW, we can verify by querying the data in SQL DW.
```sql SELECT COUNT(Value), DATEPART(mi,[timestamp]) AS [event_minute] FROM Stream_ci GROUP BY DATEPART(mi,[timestamp]) ORDER BY 2 ```
Just like that you can start querying your streaming data in SQL DW.
Conclusion
In this blog, we've covered a simple example on how you can use Azure Databricks' Structured Streaming capabilities and SQL Data Warehouse to enable near real-time analytics. The example used a rateStream and a simple write command for simplicity, but you could easily use Kafka streams as the data source and use business-specific tumbling window aggregations.
To learn more:
- Read how Azure SQL DW redefines data analytics with the latest service updates
- Read how user-controlled maintenance windows now give greater control for Azure SQL DW customers
- Read how customers get greater insights with Azure SQL DW integration and SQL Studio
- Read how you continuously monitor your Azure SQL DW workloads with SQL Vulnerability assessment
Source: Azure Blog Feed