A fast, serverless, big data pipeline powered by a single Azure Function
A single Azure function is all it took to fully implement an end-to-end, real-time, mission critical data pipeline. And it was done with a serverless architecture. Serverless architectures simplify the building, deployment, and management of cloud scale applications. Instead of worrying about data infrastructure like server procurement, configuration, and management a data engineer can focus on the tasks it takes to ensure an end-to-end and highly functioning data pipeline.
This blog describes an Azure function and how it efficiently coordinated a data ingestion pipeline that processed over eight million transactions per day.
Scenario
A large bank wanted to build a solution to detect fraudulent transactions submitted through mobile phone banking applications. The solution requires a big data pipeline approach. High volumes of real-time data are ingested into a cloud service, where a series of data transformation and extraction activities occur. This results in the creation of a feature data set, and the use of advanced analytics. For the bank, the pipeline had to be very fast and scalable, end-to-end evaluation of each transaction had to complete in less than two seconds.
Telemetry from the bank’s multiple application gateways, stream in as embedded events in complex JSON files. The ingestion technology is Azure Event Hubs. Each event is ingested into an Event Hub and parsed into multiple individual transactions. Attributes are extracted from each transaction and evaluated for fraud. The serverless architecture is constructed from these Azure services:
Pipeline architecture
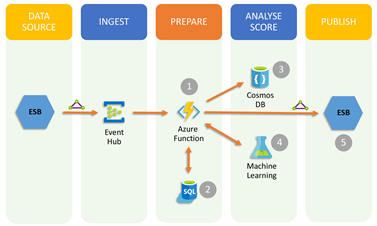
A single Azure Function was used to orchestrate and manage the entire pipeline of activities. The following diagram highlights the Azure Functions pipeline architecture:
- An enterprise system bus sends bank transaction in a JSON file that arrives into an Event Hub. The arrival triggers a response to validate and parse the ingested file.
- A SQL stored procedure is invoked. The procedure extracts data elements from the JSON message and aggregates them with customer and account profiles to generate a feature set, which is the input for a machine learning model. The aggregated message is formatted as a JSON file.
- The validated JSON message is written to Cosmos DB.
- A machine learning model is invoked to evaluate and score the transaction.
- The fraud score is posted back to an on-premises API for integration to a case management solution.

Figure 1: Azure Function pipeline architecture
Pipeline in ten steps
The Azure Function is written in C# and is composed of ten methods that are charted out in the diagram that follows. The methods include:
1. A method is triggered when an event is received by an Event Hub.
public static void Run(string myEventHubMessage, ICollector<string> resultsCollection, TraceWriter log)
2. The message is processed, and the JSON is validated.
private static void ProcessInitialMessageFromEventHub(List<string> jsonResults, string cnnString, TelemetryClient appInsights, dynamic d)
3. Invoke code to execute a SQL command to insert the message event.
private static bool CheckRequestTypeForValidMessage(dynamic d)
4. If the JSON message is valid, save it to Cosmos DB for purposes of querying later.
private static void SaveDocDb(string json, TraceWriter log)
5. Once the JSON is parsed, extract the relevant attributes.
private static string ProcessSQLReturnedFeaturesForAML(TraceWriter log, List<string>, jsonResults, TelemetryClient appInsights)
6. Execute a stored procedure to create the features that will be the input to the machine learning model.
private static string SendDataToStoredProc(dynamic d, SqlCommand spCommand, dynamic t, TelemetryClient appInsights, TransactionType transactionTypeEnum = TransactionType.Other, dynamic responseData = null)
7. Invoke a call to the Azure ML services endpoint. Obtain a score from Azure ML. Pass in the input parameters.
private static string CallAzureMl(dynamic d, TraceWriter log, HttpClient client)
8. The ML service returns a score which is then processed.
public static List<string> GetScoresFromAzureMl(string myEventHubMessage, TraceWriter log, TelemetryClient appInsights, HttpClient client)
9. Make a call to the on-premises system, passing the message as an argument.
public static List<string> ProcessMessagesIntoEsb(TraceWriter log, string cnnString, TelemetryClient appInsights, string cardNumber, string accountNumber, List<string>esbReturnMessages)
10. The score is evaluated against a threshold, which determines if it should be passed on to the on-premises case management system.
public static string CheckScoreAndProcessEsbMessages(string> myEventHubMessage, TraceWriter log, SqlCommand spCommand, TelemetryClient appInsights, string cardNumber, string accountNumber)
The figure below shows the logic as a vertical set of ten blocks, one for each task in the code.

Figure 2: Azure Function pipeline flow
Pipeline scalability
The pipeline must be responsive to extreme bursts of incoming JSON files. It must parse each file into individual transactions, and process and evaluate each transaction for fraud. After experimenting with different configuration parameters, there were some settings that were helpful to ensure the Azure function could scale as needed and process the volume of messages and transactions within the required time constraints:
- Azure Autoscale is a capability built into cloud services like Azure Functions. It is rules-based and provides the ability to scale a service like Azure Functions up or down based on defined thresholds. By default, because of the volume of data ingested into Event Hubs, the Azure Functions service scaled too quickly, and created too many instances of itself. That resulted in locking issues on the Event Hub partitions, impacting throughput significantly. After experimentation with autoscale feature, the setting for the Functions service was set to a minimum of one and a maximum of four instances.
- Two Event Hubs settings were important for ensuring performance and throughput for the Azure function:
maxBatchSize: Gets or sets the maximum event count that a user is willing to accept for processing per receive loop. This count is on a per-Event Hub partition level.
prefetchCount: Gets or sets the number of events that any receiver in the currently owned partition will actively cache. The default value for this property is 300.
After experimenting with different settings, the optimal configuration for this solution turned out to be:
// Configuration settings for 'eventHub' triggers. (Optional)
"eventHub": {
// The maximum event count received per receive loop. The default is 64.
"maxBatchSize": 10,
// The default PrefetchCount that will be used by the underlying EventProcessorHost.
"prefetchCount": 40,
// The number of event batches to process before creating an EventHub cursor checkpoint.
"batchCheckpointFrequency": 1
},
Recommended next steps
With serverless architecture, a data engineering team can focus on data flows, application logic, and service integration. If you are designing a real-time, serverless data pipeline and want the flexibility of coding your own methods for either integration with other services or to deploy through continuous integration, consider using Azure Functions to orchestrate and manage the pipeline. Check out these resources for additional information about Azure functions:
- Optimize the performance and reliability of Azure functions.
- Get started with Autoscale in Azure.
- The full architecture for the bank fraud solution referenced in this blog can be found here: Mobile Bank Fraud Solution Guide.
Special thanks to Cedric Labuschagne, Chris Cook, and Eujon Sellers for their collaboration on this blog.
Source: Azure Blog Feed