Pix2Story: Neural storyteller which creates machine-generated story in several literature genre
Storytelling is at the heart of human nature. We were storytellers long before we were able to write, we shared our values and created our societies mostly through oral storytelling. Then, we managed to find the way to record and share our stories, and certainly more advanced ways to broadly share our stories; from Gutenberg’s printing press to television, and the internet. Writing stories is not easy, especially if one must write a story just by looking at a picture in different literary genres.
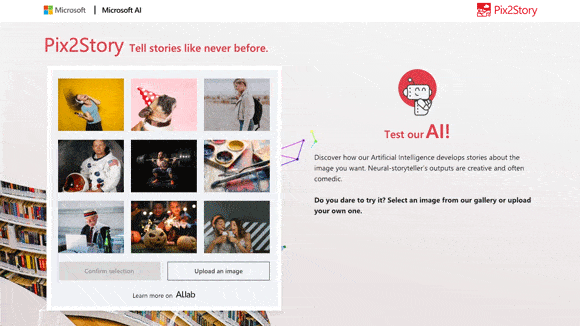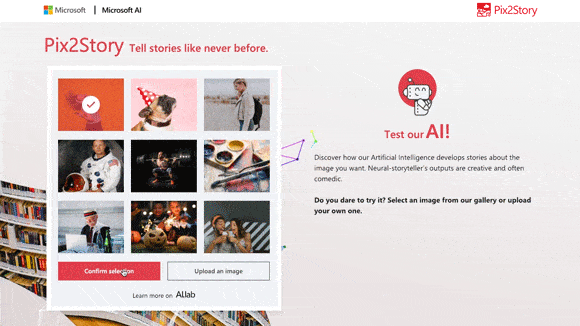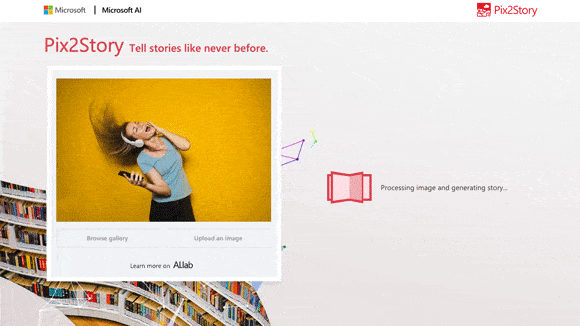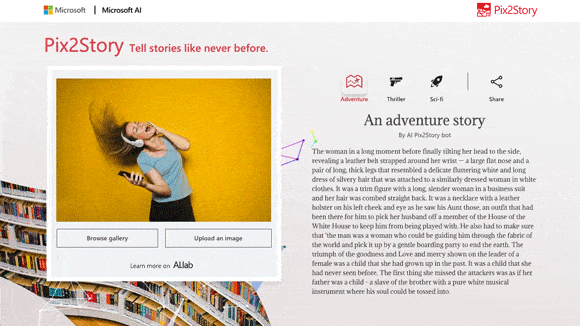
Natural Language Processing (NLP) is a field that is driving a revolution in the computer-human interaction. We have seen the amazing accuracy we have today with computer vision, but we wanted to see if we could create a more natural and cohesive narrative showcasing NLP. We developed Pix2Story a neural-storyteller web application on Azure that allows users to upload a picture and get a machine-generated story based on several literature genres. We based our work on several papers “Skip-Thought Vectors,” “Show, Attend and Tell: Neural Image Caption Generation with Visual Attention,” “Aligning Books and Movies: Towards Story-like Visual Explanations by Watching Movies and Reading Books,” and some repositories neural storyteller. The idea is to obtain the captions from the uploaded picture and feed them to the Recurrent Neural Network model to generate the narrative based on the genre and the picture.

The solution
Part of the process we have trained a visual semantic embedding model on the MS COCO captions dataset of 300.000 images to make sense of the visual input by analyzing the uploaded image and generating captions. We also transformed the captions and generate a narrative based on the selected genre: adventure, Sci-Fi, or thriller. For this, we trained for two weeks an encoder-decoder model on more than 2,000 novels. This training allows each passage of the novels to be mapped to a skip-thought vector, a way of embedding thoughts in vector space. This allowed us to understand not only words but the meaning of those words in context to reconstruct the surrounding sentences of an encoded passage. We used the new Azure Machine Learning Service as well as the Azure model management SDK with Python 3 to create the docker image with these models and deploy it using Azure Kubernetes Services (AKS) with GPU capability making the project ready to production. Let’s see the process flow in detail.
Visual semantic embedding
The first part of the project is the one that transforms the input picture into captions. Captions briefly describe the picture as is shown in the example below.

A white dog that is looking at a Frisbee Small white dog with green and white bow tie on A white dog with black spots is sitting on the grass.
The model employed to generate this caption is composed by two different networks. First, one is a convolutional neural network to extract a set of feature vectors referred to as annotation vectors.
The second part of the model is a long short-term memory (LSTM) network that produces a caption by generating one word at every time step conditioned on a context vector, the previously hidden state, and the previously generated words.

Skipthought Vectors
Skipthought Vectors by R. Kiros is a model that generates generic sentences representations that can be used in the different task. For this project, the idea is to train an encoder-decoder model that tries to reconstruct the surrounding sentences of an encoded passage using the continuity of text from books.

The model is an encoder-decoder model. The encoder is used to map a sentence into a vector. The decoder then conditions on this vector to generate a translation for the source sentence.
The vocabulary used has been expanded using google news pre-trained vectors by generating a linear regressor that maps words in the founded in books vocabulary to words in this vector.
Style shifting
Attending to skipthoughts functioning if the sentences given to the encoder from the VSE are short descriptive sentences the final output will be a short sentence. For that reason, if the desired output is a more literary passage, we need to make a style shifting. That means to operate with skipthought vectors representations to set the input to the characteristics we want to induce in the output. The operation is the following:
Skipthoughts Decoder Input = Encoded Captions of the picture – Average All Captions Encoded + Encoded Passages with similar length and features as the output we expect.
Deployment
This project has been deployed using Azure Machine Learning Services Workspaces to generate the Docker image with the files and all models involved in prediction. The deployment for consumption has been made using AKS to automatically scale the solution.

rain your own model
For training new models:
- Create conda environment:
conda env create --file environment.yml
- Activate conda env:
activate storytelling
- Set paths to your books or texts and your training settings in config.py.
- Run training.py to train an encoder, generate necessary files and train a decoder based on your texts.
- Generate bias: Mean of encoded sentences and mean of encoded captions.
- To generate stories run the following on a python console:
>import generate >story_generator = generate.StoryGenerator() >story_generator.story(image_loc='path/to/your/image')
Congratulations! You should now have a fully working application to get started. Have fun testing the project and thank you for your contribution!
"Pix2Story- Neural Storyteller"-A web app that allows users to upload a picture and get an AI generated story based on several literary genres.
Additional resources
You can find the code, solution development process and all other details on GitHub.
We hope this post helps you get started with AI and motivates you to become an AI developer.
Source: Azure Blog Feed