Under the hood: Performance, scale, security for cloud analytics with ADLS Gen2
On February 7, 2018 we announced the general availability of Azure Data Lake Storage (ADLS) Gen2. Azure is now the only cloud provider to offer a no-compromise cloud storage solution that is fast, secure, massively scalable, cost-effective, and fully capable of running the most demanding production workloads. In this blog post we’ll take a closer look at the technical foundation of ADLS that will power the end to end analytics scenarios our customers demand.
ADLS is the only cloud storage service that is purpose-built for big data analytics. It is designed to integrate with a broad range of analytics frameworks enabling a true enterprise data lake, maximize performance via true filesystem semantics, scales to meet the needs of the most demanding analytics workloads, is priced at cloud object storage rates, and is flexible to support a broad range of workloads so that you are not required to create silos for your data.
A foundational part of the platform
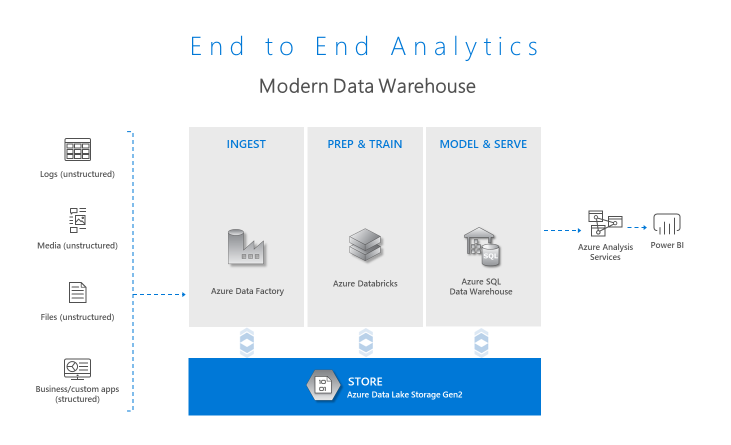
The Azure Analytics Platform not only features a great data lake for storing your data with ADLS, but is rich with additional services and a vibrant ecosystem that allows you to succeed with your end to end analytics pipelines.
Azure features services such as HDInsight and Azure Databricks for processing data, Azure Data Factory to ingress and orchestrate, Azure SQL Data Warehouse, Azure Analysis Services, and Power BI to consume your data in a pattern known as the Modern Data Warehouse, allowing you to maximize the benefit of your enterprise data lake.

Additionally, an ecosystem of popular analytics tools and frameworks integrate with ADLS so that you can build the solution that meets your needs.
“Data management and data governance is top of mind for customers implementing cloud analytics solutions. The Azure Data Lake Storage Gen2 team have been fantastic partners ensuring tight integration to provide a best-in-class customer experience as our customers adopt ADLS Gen2.”
– Ronen Schwartz, Senior Vice president & General Manager of Data Integration and Cloud Integration, Informatica
"WANDisco’s Fusion data replication technology combined with Azure Data Lake Storage Gen2 provides our customers a compelling LiveData solution for hybrid analytics by enabling easy access to Azure Data Services without imposing any downtime or disruption to on premise operations.”
– David Richards, Co-Founder and CEO, WANdisco
“Microsoft continues to innovate in providing scalable, secure infrastructure which go hand in hand with Cloudera’s mission of delivering on the Enterprise Data Cloud. We are very pleased to see Azure Data Lake Storage Gen2 roll out globally. Our mutual customers can take advantage of the simplicity of administration this storage option provides when combined with our analytics platform.”
– Vikram Makhija, General Manager for Cloud, Cloudera
Performance
Performance is the number one driver of value for big data analytics workloads. The reason for this is simple, the more performant the storage layer, the less compute (the expensive part!) required to extract the value from your data. Therefore, not only do you gain a competitive advantage by achieving insights sooner, you do so at a significantly reduced cost.
“We saw a 40 percent performance improvement and a significant reduction of our storage footprint after testing one of our market risk analytics workflows at Zurich’s Investment Management on Azure Data Lake Storage Gen2.”
– Valerio Bürker, Program Manager Investment Information Solutions, Zurich Insurance
Let’s look at how ADLS achieves overwhelming performance. The most notable feature is the Hierarchical Namespace (HNS) that allows this massively scalable storage service to arrange your data like a filesystem with a hierarchy of directories. All analytics frameworks (eg. Spark, Hive, etc.) are built with an implicit assumption that the underlying storage service is a hierarchical filesystem. This is most obvious when data is written to temporary directories which are renamed at the completion of the job. For traditional cloud-based object stores, this is an O(n) complex operation, n copies and deletes, that dramatically impacts performance. In ADLS this rename is a single atomic metadata operation.

The other contributor to performance is the Azure Blob Filesystem (ABFS) driver. This driver takes advantage of the fact that the ADLS endpoint is optimized for big data analytics workloads. These workloads are most sensitive to maximizing throughput via large IO operations, as distinct from other general purpose cloud stores that must optimize for a much larger range of IO operations. This level of optimization leads to significant IO performance improvements that directly benefits the performance and cost aspects of running big data analytics workloads on Azure. The ABFS driver is contributed as part of Apache Hadoop® and is available in HDInsight and Azure Databricks, as well as other commercial Hadoop distributions.
Scalable
Scalability for big data analytics is also critically important. There’s no point having a solution that works great for a few TBs of data, but collapses as the data size inevitably grows. The rate of growth of big data analytics projects tend to be non-linear as a consequence of more diverse and accessible sources of data. Most projects do benefit from the principle that the more data you have, the better the insights. However, this leads to design challenges such that the system must scale at the same rate as the growth of the data. One of the great design pivots of big data analytics frameworks, such as Hadoop and Spark, is that they scale horizontally. What this means is that as the data and/or processing grows, you can just add more nodes to your cluster and the processing continues unabated. This, however, relies on the storage layer scaling linearly as well.
This is where the value of building ADLS on top of the existing Azure Blob service shines. The EB scale of this service now applies to ADLS ensuring that no limits exist on the amount of data to be stored or accessed. In practical terms, customers can store 100s of PB of data which can be accessed with throughput to satisfy the most demanding workloads.

Secure
For customers wanting to build a data lake to serve the entire enterprise, security is no lightweight consideration. There are multiple aspects to providing end to end security for your data lake:
- Authentication – Azure Active Directory OAuth bearer tokens provide industry standard authentication mechanisms, backed by the same identity service used throughout Azure and Office365.
- Access control – A combination of Azure Role Based Access Control (RBAC) and POSIX-compliant Access Control Lists (ACLs) to provide flexible and scalable access control. Significantly, the POSIX ACLs are the same mechanism used within Hadoop.
- Encryption at rest and transit – Data stored in ADLS is encrypted using either a system supplied or customer managed key. Additionally, data is encrypted using TLS 1.2 whilst in transit.
- Network transport security – Given that ADLS exposes endpoints on the public Internet, transport-level protections are provided via Storage Firewalls that securely restrict where the data may be accessed from, enforced at the packet level.
Tight integration with analytics frameworks results in an end to end secure pipeline. The HDInsight Enterprise Security Package makes end-user authentication flow through the cluster and to the data in the data lake.
Get started today!
We’re excited for you to try Azure Data Lake Storage! Get started today and let us know your feedback.
- Get started with Azure Data Lake Storage.
- Watch the video, “Create your first ADLS Gen2 Data Lake.”
- Read the general availability announcement.
- Learn how ADLS improves the Azure analytics platform in the blog post, “Individually great, collectively unmatched: Announcing updates to 3 great Azure Data Services.”
- Refer to the Azure Data Lake Storage documentation.
- Learn how to deploy a HDInsight cluster with ADLS.
- Deploy an Azure Databricks workspace with ADLS.
- Ingest data into ADLS using Azure Data Factory.
Source: Azure Blog Feed