ONNX Runtime integration with NVIDIA TensorRT in preview
Today we are excited to open source the preview of the NVIDIA TensorRT execution provider in ONNX Runtime. With this release, we are taking another step towards open and interoperable AI by enabling developers to easily leverage industry-leading GPU acceleration regardless of their choice of framework. Developers can now tap into the power of TensorRT through ONNX Runtime to accelerate inferencing of ONNX models, which can be exported or converted from PyTorch, TensorFlow, and many other popular frameworks.
Microsoft and NVIDIA worked closely to integrate the TensorRT execution provider with ONNX Runtime and have validated support for all the ONNX Models in the model zoo. With the TensorRT execution provider, ONNX Runtime delivers better inferencing performance on the same hardware compared to generic GPU acceleration. We have seen up to 2X improved performance using the TensorRT execution provider on internal workloads from Bing MultiMedia services.
How it works
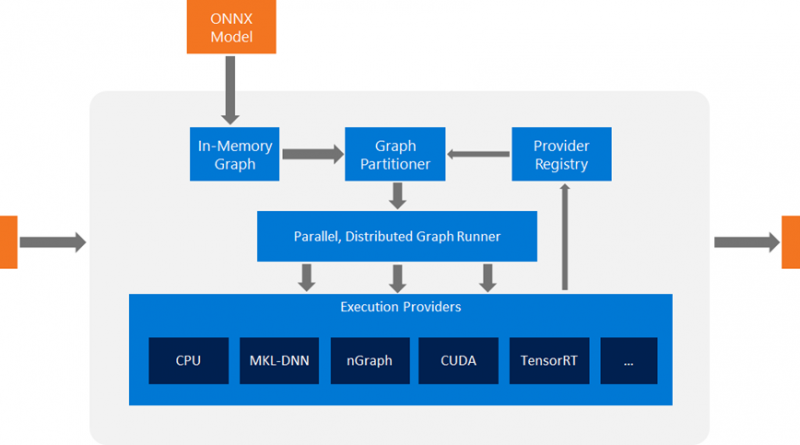
ONNX Runtime together with its TensorRT execution provider accelerates the inferencing of deep learning models by parsing the graph and allocating specific nodes for execution by the TensorRT stack in supported hardware. The TensorRT execution provider interfaces with the TensorRT libraries that are preinstalled in the platform to process the ONNX sub-graph and execute it on NVIDIA hardware. This enables developers to run ONNX models across different flavors of hardware and build applications with the flexibility to target different hardware configurations. This architecture abstracts out the details of the hardware specific libraries that are essential to optimizing the execution of deep neural networks.

How to use the TensorRT execution provider
ONNX Runtime together with the TensorRT execution provider supports the ONNX Spec v1.2 or higher, with version 9 of the Opset. TensorRT optimized models can be deployed to all N-series VMs powered by NVIDIA GPUs on Azure.
To use TensorRT, you must first build ONNX Runtime with the TensorRT execution provider (use --use_tensorrt --tensorrt_home <path to location for TensorRT libraries in your local machine> flags in the build.sh tool). You can then take advantage of TensorRT by initiating the inference session through the ONNX Runtime APIs. ONNX Runtime will automatically prioritize the appropriate sub-graphs for execution by TensorRT to maximize performance.
InferenceSession session_object{so};
session_object.RegisterExecutionProvider(std::make_unique<::onnxruntime::TensorrtExecutionProvider>());
status = session_object.Load(model_file_name);
Detailed instructions are available on GitHub. In addition, a collection of standard tests are available through the onnx_test_runner utility in the repo to help verify the ONNX Runtime build with TensorRT execution provider.
What is ONNX and ONNX Runtime
ONNX is an open format for deep learning and traditional machine learning models that Microsoft co-developed with Facebook and AWS. ONNX allows models to be represented in a common format that can be executed across different hardware platforms using ONNX Runtime. This gives developers the freedom to choose the right framework for their task, as well as the confidence to run their models efficiently on a variety of platforms with the hardware of their choice.
ONNX Runtime is the first publicly available inference engine with full support for ONNX 1.2 and higher including the ONNX-ML profile. ONNX Runtime is lightweight and modular with an extensible architecture that allows hardware accelerators such as TensorRT to plug in as “execution providers.” These execution providers unlock low latency and high efficiency neural network computations. Today, ONNX Runtime powers core scenarios that serve billions of users in Bing, Office, and more.
Another step towards open and interoperable AI
The preview of the TensorRT execution provider for ONNX Runtime marks another milestone in our venture to create an open and interoperable ecosystem for AI. We hope this makes it easier to drive AI innovation in a world with ever-increasing latency requirements for production models. We are continuously evolving and improving ONNX Runtime, and look forward to your feedback and contributions!
To learn more about using ONNX for accelerated inferencing on the cloud and edge, check out the ONNX session at NVIDIA GTC. Have feedback or questions about ONNX Runtime? File an issue on GitHub, and follow us on Twitter.
Source: Azure Blog Feed