How to accelerate DevOps with Machine Learning lifecycle management
DevOps is the union of people, processes, and products to enable the continuous delivery of value to end users. DevOps for machine learning is about bringing the lifecycle management of DevOps to Machine Learning. Utilizing Machine Learning, DevOps can easily manage, monitor, and version models while simplifying workflows and the collaboration process.
Effectively managing the Machine Learning lifecycle is critical for DevOps’ success. And the first piece to machine learning lifecycle management is building your machine learning pipeline(s).
What is a Machine Learning Pipeline?
DevOps for Machine Learning includes data preparation, experimentation, model training, model management, deployment, and monitoring while also enhancing governance, repeatability, and collaboration throughout the model development process. Pipelines allow for the modularization of phases into discrete steps and provide a mechanism for automating, sharing, and reproducing models and ML assets. They create and manage workflows that stitch together machine learning phases. Essentially, pipelines allow you to optimize your workflow with simplicity, speed, portability, and reusability.
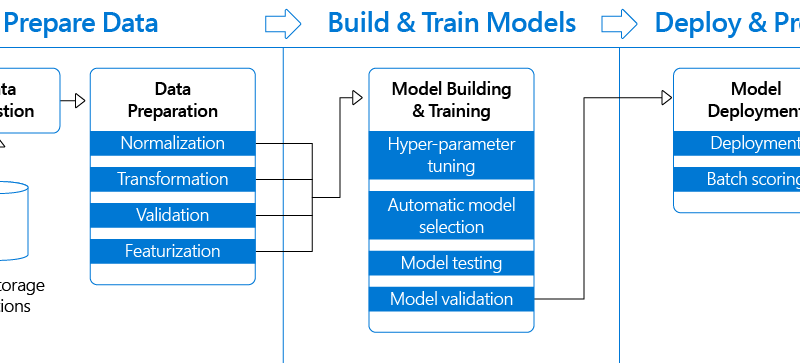
There are four steps involved in deploying machine learning that data scientists, engineers and IT experts collaborate on:
- Data Ingestion and Preparation
- Model Training and Retraining
- Model Evaluation
- Deployment

Together, these steps make up the Machine Learning pipeline. Below is an excerpt from documentation on building machine pipelines with Azure Machine Learning service, which explains it well.
“Using distinct steps makes it possible to rerun only the steps you need, as you tweak and test your workflow. A step is a computational unit in the pipeline. As shown in the preceding diagram, the task of preparing data can involve many steps. These include, but aren't limited to, normalization, transformation, validation, and featurization. Data sources and intermediate data are reused across the pipeline, which saves compute time and resources.”
4 benefits of accelerating Machine Learning pipelines for DevOps
1. Collaborate easily across teams
- Data scientists, data engineers, and IT professionals using machine learning pipelines need to collaborate on every step involved in the machine learning lifecycle: from data prep to deployment.
- Azure Machine Learning service workspace is designed to make the pipelines you create visible to the members of your team. You can use Python to create your machine learning pipelines and interact with them in Jupyter notebooks, or in another preferred integrated development environment.
2. Simplify workflows
- Data prep and modeling can last days or weeks, taking time and attention away from other business objectives.
- The Azure Machine Learning SDK offers imperative constructs for sequencing and parallelizing the steps in your pipelines when no data dependency is present. You can also templatize pipelines for specific scenarios and deploy them to a REST endpoint, so you can schedule batch-scoring or retraining jobs. You only need to rerun the steps you need, as you tweak and test your workflow when you rerun a pipeline.
3. Centralized Management
- Tracking models and their version histories is a hurdle many DevOps teams face when building and maintaining their machine learning pipelines.
- The Azure Machine Learning service model registry tracks models, their version histories, their lineage and artifacts. Once the model is in production, the Application Insights service collects both application and model telemetry that allows the model to be monitored in production for operational and model correctness. The data captured during inferencing is presented back to the data scientists and this information can be used to determine model performance, data drift, and model decay, as well as the tools to train, manage, and deploy machine learning experiments and web services in one central view.
- The Azure Machine Learning SDK also allows you to submit and track individual pipeline runs. You can explicitly name and version your data sources, inputs, and outputs instead of manually tracking data and result paths as you iterate. You can also manage scripts and data separately for increased productivity. For each step in your pipeline. Azure coordinates between the various compute targets you use, so that your intermediate data can be shared with the downstream compute targets easily. You can track the metrics for your pipeline experiments directly in the Azure portal.
4. Track your experiments easily
- DevOps capabilities for machine learning further improve productivity by enabling experiment tracking and management of models deployed in the cloud and on the edge. All these capabilities can be accessed from any Python environment running anywhere, including data scientists’ workstations. The data scientist can compare runs, and then select the “best” model for the problem statement.
- The Azure Machine Learning workspace keeps a list of compute targets that you can use to train your model. It also keeps a history of the training runs, including logs, metrics, output, and a snapshot of your scripts. Create multiple workspaces or common workspaces to be shared by multiple people.
Conclusion
As you can see, DevOps for Machine Learning can be streamlined across the ML pipeline with more visibility into training, experiment metrics, and model versions. Azure Machine Learning service, seamlessly integrates with Azure services to provide end-to-end capabilities for the entire Machine Learning lifecycle, making it simpler and faster than ever.
This is part two of a four-part series on the pillars of Azure Machine Learning services. Check out part one if you haven’t already, and be sure to look out for our next blog, where we’ll be talking about ML at scale.
Learn More
Visit our product site to learn more about the Azure Machine Learning service, and get started with a free trial of Azure Machine Learning service.
Source: Azure Blog Feed