PyTorch on Azure: Full support for PyTorch 1.2
Congratulations to the PyTorch community on the release of PyTorch 1.2! Last fall, as part of our dedication to open source AI, we made PyTorch one of the primary, fully supported training frameworks on Azure. PyTorch is supported across many of our AI platform services and our developers participate in the PyTorch community, contributing key improvements to the code base. Today we would like to share the many ways you can use PyTorch 1.2 on Azure and highlight some of the contributions we’ve made to help customers take their PyTorch models from training to production.
PyTorch 1.2 on Azure
Getting started with PyTorch on Azure is easy and a great way to train and deploy your PyTorch models. We’ve integrated PyTorch 1.2 in the following Azure services so you can utilize the latest features:
- Azure Machine Learning service – Azure Machine Learning streamlines the building, training, and deployment of machine learning models. Azure Machine Learning’s Python SDK has a dedicated PyTorch estimator that makes it easy to run PyTorch training scripts on any compute target you choose, whether it’s your local machine, a single virtual machine (VM) in Azure, or a GPU cluster in Azure. Learn how to train Pytorch deep learning models at scale with Azure Machine Learning.
- Azure Notebooks – Azure Notebooks provides a free, cloud-hosted Jupyter notebook server with PyTorch 1.2 pre-installed. To learn more, check out the PyTorch tutorials and examples.
- Data Science Virtual Machine – Data Science Virtual Machines are pre-configured with popular data science and deep learning tools, including PyTorch 1.2. You can choose a variety of machine types to host your Data Science Virtual Machine, including those with GPUs. To learn more, refer to the Data Science Virtual Machine documentation.
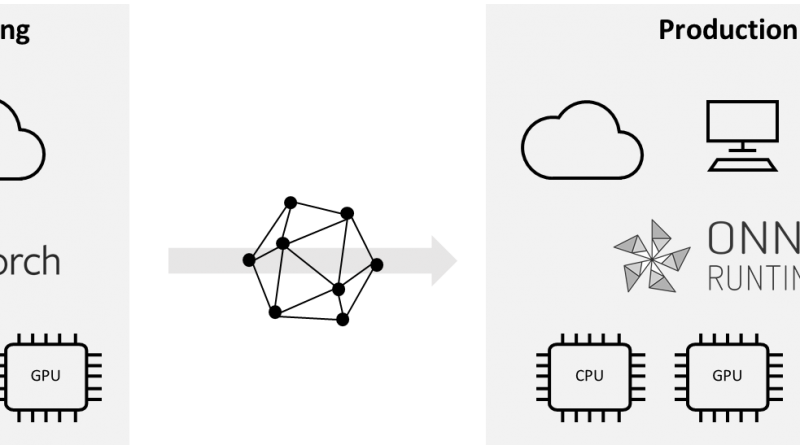
From PyTorch to production
PyTorch is a popular open-source deep learning framework for creating and training models. It is built to use the power of GPUs for faster training and is deeply integrated with Python, making it easy to get started. However, deploying trained models to production has historically been a pain point for customers. For production environments, using Python for the core computations may not be suitable due to performance and multi-threading requirements. To address this challenge, we collaborated with the PyTorch community to make it easier to use PyTorch trained models in production.
PyTorch’s JIT compiler transitions models from eager mode to graph mode using tracing, TorchScript, or a mix of both. We then recommend using PyTorch’s built-in support for ONNX export. ONNX stands for Open Neural Network Exchange and is an open standard format for representing machine learning models. ONNX models can be inferenced using ONNX Runtime. ONNX Runtime is an inference engine for production scale machine learning workloads that are open source, cross platform, and highly optimized. Written in C++, it runs on Linux, Windows, and Mac. Its small binary size makes it suitable for a range of target devices and environments. It’s accelerated on CPU, GPU, and VPU thanks to Intel and NVIDIA who have integrated their accelerators with ONNX Runtime.

In PyTorch 1.2, we contributed enhanced ONNX export capabilities:
- Support for a wider range of PyTorch models, including object detection and segmentation models such as mask RCNN, faster RCNN, and SSD
- Support for models that work on variable length inputs
- Export models that can run on various versions of ONNX inference engines
- Optimization of models with constant folding
- End-to-end tutorial showing export of a PyTorch model to ONNX and running inference in ONNX Runtime
You can deploy your own PyTorch models to various production environments with ONNX Runtime. Learn more at the links below:
Next steps
We are very excited to see PyTorch continue to evolve and improve. We are proud of our support for and contributions to the PyTorch community. PyTorch 1.2 is now available on Azure—start your free trial today.
We look forward to hearing from you as you use PyTorch on Azure.
Source: Azure Blog Feed