Apache Spark to Azure #CosmosDB Connector is now generally available
We are happy to announce that the Apache Spark to Azure Cosmos DB Connector is now generally available. It enables real-time data analytics and data science, machine learning, and exploration over globally distributed data in Azure Cosmos DB. Connecting Apache Spark to Azure Cosmos DB accelerates our customer’s ability to solve fast-moving data science problems, where data can be quickly persisted and queried using Azure Cosmos DB. The Apache Spark to Azure Cosmos DB connector efficiently exploits the native Azure Cosmos DB managed indexes that enable updateable columns when performing analytics and push-down predicate filtering against fast-changing globally-distributed data, ranging from IoT, data science, and analytics scenarios. The Apache Spark to Azure Cosmos DB connector uses the Java Reactive Extension (Rx) for Microsoft Azure Cosmos DB SDK.

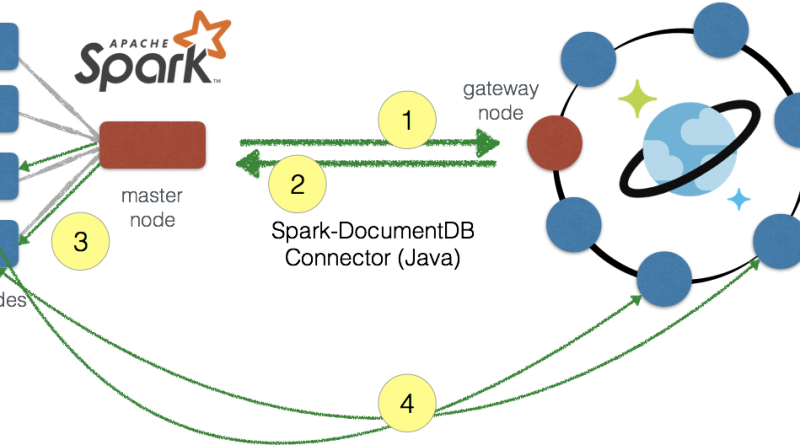
Figure 1: With Apache Spark Connector for Azure Cosmos DB, data is parallelized between the Apache Spark worker nodes and Azure Cosmos DB data partitions.
With the Spark Connector for Azure Cosmos DB, the metadata detailing the location of the data within the Azure Cosmos DB data partitions is provided to the Spark master node (steps 1 and 2). Thus, when processing, the data is parallelized between the Spark worker nodes and Azure Cosmos DB data partitions (steps 3 and 4). Therefore, your data is stored in Azure Cosmos DB, you will get the performance, scalability, throughput, and consistency all backed by Azure Cosmos DB when you are solving your machine learning and data science problems with Apache Spark.
You can get started today and download the Spark connector from GitHub! The azure-cosmosdb-spark GitHub repo also includes sample notebooks including:
- On-time Flight Performance with Apache Spark and Azure Cosmos DB: This notebook also includes distributed analytics, GraphFrames, and ML (logistic regression) examples.
- Apache Spark and Azure Cosmos DB Change Feed: This notebook provides examples of how to have Apache Spark interact with the Azure Cosmos DB Change Feed.
- Twitter with Apache Spark and Azure Cosmos DB Change Feed: Super charging the Azure Cosmos DB change feed notebook to include a real-time Twitter source.
- Using Apache Spark to query Azure Cosmos DB Graphs: A multi-model example where you can run gremlin queries against your Azure Cosmos DB graph container and query the same container using Apache Spark via the Core API.
Performance improvements
Since we first announced the Spark connector earlier in the year, we have received a lot of feedback through azure-cosmosdb-spark GitHub issues, and direct interactions via askcosmosdb@microsoft.com. Unequivocally, one of the most important set of improvements to the Spark connector since its preview was to improve performance such as:
- Added more Spark Connector connection policy configurations. For more information, please refer to configuration references.
- Added support for multiple Spark versions
- Improved throughput when writing to Azure Cosmos DB
- Added support for Azure Cosmos DB change feed
- Addressed various bug fixes
Support for structured streaming
From a feature perspective, the most requested ask was to enable support for structured streaming. For example, the following code sample provides how to do an interval count using Spark structured streaming and Azure Cosmos DB Change Feed, as well as pushing the output to the console.
import com.microsoft.azure.cosmosdb.spark._
import com.microsoft.azure.cosmosdb.spark.schema._
import com.microsoft.azure.cosmosdb.spark.config.Config
import org.codehaus.jackson.map.ObjectMapper
import com.microsoft.azure.cosmosdb.spark.streaming._
import java.time._
val sourceConfigMap = Map(
"Endpoint" -> "COSMOS DB ENDPOINT",
"Masterkey" -> "COSMOS DB KEY",
"Database" -> "DATABASE",
"Collection" -> "COLLECTION",
"ConnectionMode" -> "Gateway",
"ChangeFeedCheckpointLocation" -> "checkpointlocation",
"changefeedqueryname" -> "Streaming Query from Azure Cosmos DB Change Feed Internal Count")
// Start reading change feed as a stream
var streamData = spark.readStream.format(classOf[CosmosDBSourceProvider].getName).options(sourceConfigMap).load()
// Start streaming query to console sink
val query = streamData.withColumn("countcol", streamData.col("id").substr(0, 0)).groupBy("countcol").count().writeStream.outputMode("complete").format("console").start()
The streaming output, in this case we are using a Twitter stream that is pushing data into Azure Cosmos DB, looks similar to below.
------------------------------------------- Batch: 0 ------------------------------------------- +--------+-----+ |countcol|count| +--------+-----+ +--------+-----+ ------------------------------------------- Batch: 1 ------------------------------------------- +--------+-----+ |countcol|count| +--------+-----+ +--------+-----+ ... ------------------------------------------- Batch: 5 ------------------------------------------- +--------+-----+ |countcol|count| +--------+-----+ | | 8108| +--------+-----+ ------------------------------------------- Batch: 6 ------------------------------------------- +--------+-----+ |countcol|count| +--------+-----+ | |21040| +--------+-----+ ... ------------------------------------------- Batch: 13 ------------------------------------------- +--------+-----+ |countcol|count| +--------+-----+ | |99907| +--------+-----+
For more information, please refer to:
- azure-cosmosdb-spark Structured Streams demos
- Stream Processing Changes using Azure Cosmos DB Change Feed and Apache Spark
Next steps
The Apache Spark to Azure Cosmos DB Connector enables both ad-hoc and interactive queries on real-time big data, as well as advanced analytics, data science, machine learning and artificial intelligence. Azure Cosmos DB can be used for capturing data that is collected incrementally from various sources across the globe. This includes social analytics, time series, game or application telemetry, retail catalogs, up-to-date trends and counters, and audit log systems. To dive deeper into all of the scenarios, please refer to the azure-cosmosdb-spark GitHub wiki including:
- Azure Cosmos DB Spark Connecter user guide
- Distributed Aggregations examples
- Stream Processing changes using Azure Cosmos DB Change Feed and Apache Spark
- Change Feed demos
- Structured Streams demos
To get started running queries, create a new Azure Cosmos DB account from the Azure Portal and work with the project in our azure-cosmosdb-spark GitHub repo. You can try Azure Cosmos DB for free without an Azure subscription, free of charge and commitments.
If you need any help or have questions or feedback, please reach out to us on the developer forums on Stack Overflow. Stay up-to-date on the latest Azure Cosmos DB news and features by following us on Twitter #CosmosDB and @AzureCosmosDB.
— Your friends at Azure Cosmos DB (@AzureCosmosDB, #CosmosDB)
Source: Azure Blog Feed