Qubole customers now gain insights from Azure Data Lake
Azure Data Lake provides one of the easiest ways to build an enterprise data lake. With Qubole’s latest release of Qubole Data Service (QDS), their customers can now land data of any size, structured or unstructured, in the data lake for analytics. Access to a data lake is essential in gaining insights on enterprise data and driving new business opportunities. Life just got easier for enterprises transitioning from legacy on-premises data warehouses to Azure Data Lake using Qubole.
Try it out today!
You can easily deploy the latest release of QDS from the Azure Marketplace. The Azure Quick Start Guide provides step-by-step guidance for configuring QDS to interoperate with Azure Data Lake Store.

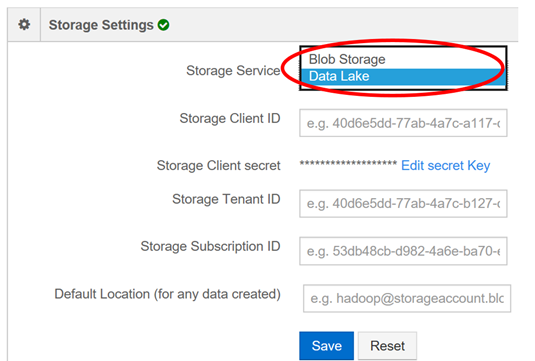
In QDS, in Control Panel go to Account Settings, under Account Details
choose Storage Service and choose Data Lake in the drop down.
Qubole Data Service (QDS) delivers fully-automated and cloud-optimized data engines (including Spark, Hive, and Hadoop MapReduce) on Azure, performing at scale with extensive automation management tools. Along with its existing support for Zeppelin notebooks, Qubole also recently announced support for Jupyter notebooks enabling data scientists to connect to a Qubole Spark cluster from within their IDE and execute distributed computing on large datasets that reside in Azure Data Lake.
Azure Data Lake provides a high throughput, cloud-scale filesystem optimized for analytics workloads. Multiple clusters can share the same Azure Data Lake account, enabling customers to add and remove compute resources to meet workloads’ needs. Through Role-based Access Control (RBAC), and POSIX-style ACLs at file and folder level, customers can either partition the data lake among separate users or share data lake among multiple users concurrently. Encryption-at-rest and integration with Azure Key Vault enables customers to secure their data lake assets with either Azure-generated keys, or keys they create themselves. With today’s announcement, analytics workloads on Qubole clusters can now easily access data in Azure Data Lake and take advantage of these capabilities, bringing Qubole's intelligence, automation and data platforms capabilities to Azure Data Lake.

Source: Big Data