Highlighting 3 New Features in Azure Data Factory V2
Having just announced the V2 preview availability of Azure Data Factory at Ignite in Orlando, I'm going to start a new blog series focusing on three new features in Azure Data Factory for different types of data integration users. These features are all available now, in preview, in the ADF V2 service. So, for part one of this series, I’ll focus on Data Engineers who build and maintain ETL processes. There are very important parts of building production-ready data pipelines:
1. Control Flow
For SSIS ETL developers, Control Flow is a common concept in ETL jobs, where you build data integration jobs within a workflow that allows you to control execution, looping, conditional execution, etc. ADF V2 introduces similar concepts within ADF Pipelines as a way to provide control over the logical flow of your data integration pipeline. In the updated description of Pipelines and Activities for ADF V2, you'll notice Activities broken-out into Data Transformation activities and Control activities. The Control activities in ADF will now allow you to loop, retrieve metadata and lookup from external sources, as found in documentation.
2. Parameterized Pipelines
We've added the ability to parameterize pipelines, which can be used in conjunction with expressions and triggers (see triggers below under Scheduling) in new and exciting ways when defining data pipelines in ADF.
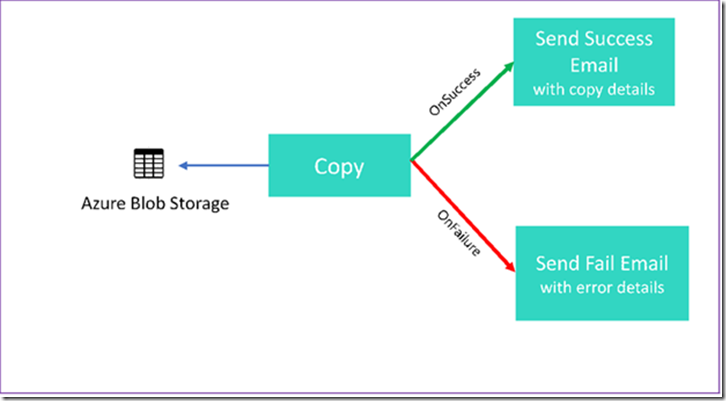
Here is an example of using parameters to chain activities and to conditionally execute the next activity in the pipeline so that you can an email and perform next actions on the data sets. This also demonstrates another new ADF activity, the Web activity which is used, in this case, to send an email. To learn more, please visit documentation.

3. Flexible Scheduling
We've changed the scheduling model for ADF so that when you build a pipeline in ADF V2, you will no longer build dataset-based time slices, data availability and pipeline time windows. Instead, you will attach separate Trigger resources that you can then use to reference pipelines that you've built and execute them on a wall-clock style schedule. As mentioned above, Triggers also support passing parameters to your pipelines, meaning that you can create general-use pipelines and then leverage parameters to invoke specific-use instances of those pipelines from your trigger. For the preview period, take a look at using the wall-clock calendar scheduling, which is an update to our ADF scheduling model from the time-slice dataset use case in V1. During the preview of the V2 ADF service, we will continue to add more Trigger types that you can use to execute your pipelines automatically.
Once you’ve built your data pipelines and schedules in Azure Data Factory V2, you’ll need to monitor those ETL jobs on a regular basis. During this initial preview period of the ADF V2 service, monitor your pipelines via PowerShell, Azure Monitor or .NET. We also just announced the preview for the new visual monitoring experience in the V2 ADF service. Here is how to get started with that monitoring experience.
Source: Azure Blog Feed