Implementation patterns for big data and data warehouse on Azure
To help our customers with their adoption of Azure services for big data and data warehousing workloads we have identified some common adoption patterns which are reference architectures for success. So, what patterns do we have for our modern data warehouse play?
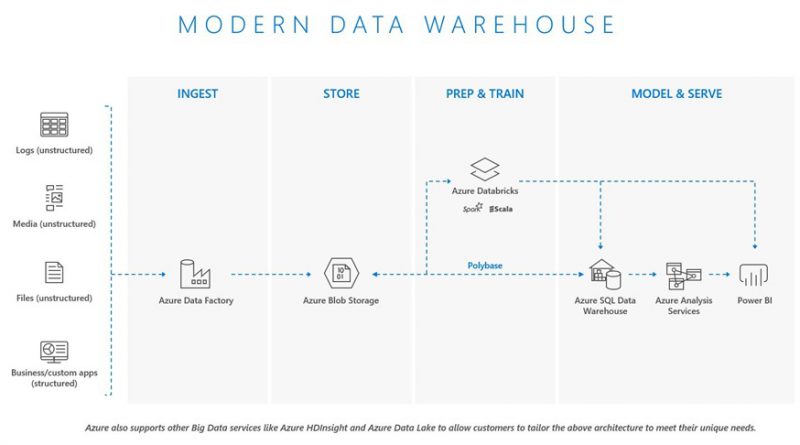
Modern data warehouse
This is the convergence of relational and non-relational, or structured and unstructured data orchestrated by Azure Data Factory coming together in Azure Blob Storage to act as the primary data source for Azure services. The value of having the relational data warehouse layer is to support the business rules, security model, and governance which are often layered here. The de-normalization of the data in the relational model is purposeful as it aligns data models and schemas to support various internal business organizations and applications. Azure Databricks can also cleanse data prior to loading into Azure SQL Data Warehouse. It enables an optional analytical path in addition to the Azure Analysis Services layer for business intelligence applications such as Power BI or other business applications.

Advanced analytics on big data
Here we introduce advanced analytical capabilities through our Azure Databricks platforms with Azure Machine Learning. We still have all the greatness of Azure Data Factory, Azure Blob Storage, and Azure SQL Data Warehouse. We build on the modern data warehouse pattern to add new capabilities and extend the data use case into driving advanced analytics and model training. Data scientists are using our Azure Machine Learning capabilities in this way to test experimental models against large, historical, and factual data sets to provide more breadth and credibility to model scores. Modern and intelligent application integration is enabled through the use of Azure Cosmos DB which is ideal for supporting different data requirements and consumption.

Real-time analytics (Lambda)
We introduce Azure IOT Hub and Apache Kafka alongside Azure Databricks to deliver a rich, real-time analytical model alongside batch-based workloads. Here we take everything from the previous patterns and introduce a fast ingestion layer which can execute data analytics on the inbound data in parallel alongside existing batch workloads. You could use Azure Stream Analytics to do the same thing, and the consideration being made here is the high probability of join-capability with inbound data against current stored data. This may or may not be a factor in the lambda requirements, and due diligence should be applied based on the use case. We can see that there is still support for modern and intelligent application integration using Azure Cosmos DB and this completes the build-out of the use cases from our foundation Modern Data Warehouse pattern.

I hope the information shared has been helpful and we look forward to hearing your feedback on the patterns shared in this article.
Source: Azure Blog Feed